FMG研报:AI的三个问题和DePIN的解法



摘要
AI时代产品竞争,离不开资源端(算力、数据等),尤其是稳定资源端做支持。
模型训练/迭代同时还需要庞大的用户标的(IP)来帮忙喂养资料,来对模型效率产生质变。
与Web3的结合,能够帮助中小型AI初创团队实现对传统AI巨头的弯道超车。
对于DePIN生态,算力、带宽等资源端决定下限(单纯算力集成没有护城河);AI模型的应用、深度优化(类似BitTensor)、专业化(Render、Hivemaper)以及对数据的有效利用等维度决定项目上限。
AI+DePIN语境下,模型推理 & 微调,以及移动端AI模型市场将得到重视。
AI市场分析 & 三个问题
有数据统计,从2022年9月,ChatGPT诞生前夕到2023年8月,全球Top 50的AI产品就产生了超过240亿次的访问量,平均每月增长量为2.363亿次。
AI产品的繁荣,背后是对于算力依赖程度的加剧。
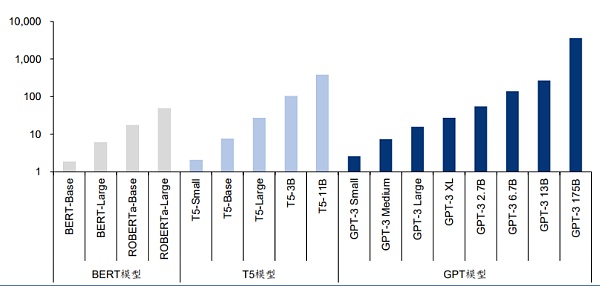
Source: "Language Models are Few-Shot Learners"
马萨诸塞大学阿莫斯特分校的一篇论文指出,“训练一个人工智能模型,其一生所排放的碳相当于五辆汽车的碳排放量。” 然而,这一分析仅涉及一次训练。当模型通过反复训练得到改进时,能量的使用将会大大增加。
最新的语言模型包含数十亿甚至数万亿的权重。一种流行的模型GPT-3拥有1750亿个机器学习参数。如果使用A100需要1024个GPU、34天和460万美元来训练该模型。
后AI时代的产品竞争,已经逐渐延展成为以算力为主的资源端战争。

Source:AI is harming our planet: addressing AI’s staggering energy cost
这就延展出三个问题:第一,一个AI产品是否有足够的资源端(算力、带宽等)尤其是稳定资源端做支持。这种可靠需要算力足够的去中心化。在传统领域,由于芯片需求端的缺口,再加上基于政策、意识形态构建的世界墙,让芯片制造商天然处于优势地位,并能够大幅度哄抬价格。比如NVIDIA H100型号芯片从2023年4月份的3.6万美元涨至5万美元,这进一步加重了AI模型训练团队的成本。
第二个问题,资源端条件的满足帮助AI项目解决了硬件刚需,但模型训练/迭代同时还需要庞大的用户标的(IP)来帮忙喂养资料。模型规模超过一定阈值之后,在不同任务上的性能都表现出突破式增长。
第三个问题在:中小型AI初创团队难以实现弯道超车。传统金融市场算力的垄断性也导致AI模型方案也存在垄断性,以OPenAI、Google Deepmind等为代表的大型AI模型厂商正在进一步构建自己的护城河。中小型AI团队需要谋求更多的差异化竞争。
以上三个问题,都可以从Web3中找到答案。事实上,AI与Web3的结合由来已久,并且生态较为繁荣。
下图为Future Money Group制作的AI+Web3生态的部分赛道&项目展示。
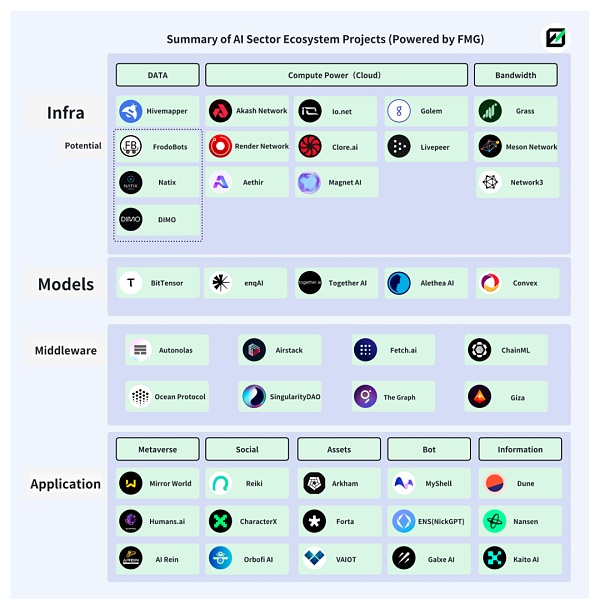
AI+DePIN
1. DePIN的解决方案
DePIN是去中心化物理基础设施网络的缩写,同时也是人和设备的生产关系集合,通过代币经济学与硬件设备(比如计算机、车载摄像头等)的结合,来将用户与设备进行有机结合,同时实现经济模型的有序运转。
相较于定义更广泛的Web3,由于DePIN天然与硬件设备和传统企业有更深的关联,因此DePIN在吸引场外AI团队和相关资金方面有着天然的优势。
DePIN生态对于分布式算力的追求和贡献者的激励,恰好解决了AI产品对于算力和IP的需求。
DePIN以代币经济学来推动世界算力(算力中心 & 闲置个人算力)的入驻,降低了算力的中心化风险,同时降低了AI团队调用算力的成本。
DePIN生态数量庞大、多元化的IP构成帮助AI模型能够实现数据获取渠道的多样性和客观性,足够多的数据提供者也能确保AI模型性能的提升。
DePIN生态用户与Web3用户在人物画像上的重叠,能够帮助入驻的AI项目开发出更多带有Web3特色的AI模型,形成差异化竞争,这是传统AI市场所不具备的。
在Web2领域,AI模型数据采集通常来自公开数据集或模型制作方自行收集,这就会受到文化背景和地域的限制,让AI模型产出的内容存在主观性“失真”。传统数据采集方式又受限于采集效率和成本,难以获得更大的模型规模(参数数量、训练时长和数据质量)。对于AI模型而言,模型规模越大,模型的性能越容易引起质变。

Source:Large Language Models’ emergent abilities: how they solve problems they were not trained to address?
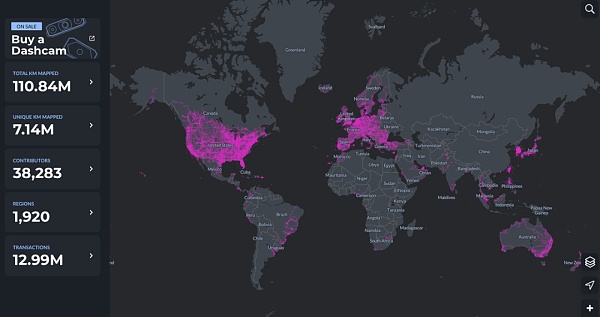
DePIN恰好在这一领域有着天然优势。以Hivemapper为例,分布于全球1920个地区,接近4万名贡献者在为MAP AI(地图AI模型)提供着数据。
AI与DePIN的结合还意味着AI与Web3的融合上升了新的高度。当前Web3中的AI项目,广泛爆发于应用端,并且几乎没有摆脱对Web2基础设施的直接依赖,即将依托于传统算力平台的已有AI模型植入到Web3项目中,对于AI模型的创建则很少涉猎。
Web3要素一直处于食物链下游,无法获得真正的超额回报。对于分布式算力平台而言也是如此,单纯的AI+算力,并不能真正挖掘出二者的潜力,在这一关系中,算力提供方无法获得更多超额利润,且生态架构过于单一,因此也就无法通过代币经济学去促使飞轮运转。
但AI+DePIN概念,正在打破这一固有关系,并将Web3的注意力转移至更广阔的AI模型方面。
2. AI+DePIN项目汇总
DePIN内部天然拥有AI所亟需的设备(算力、带宽、算法、数据)、用户(模型训练数据提供者),以及生态内激励机制(代币经济学)。
我们可以大胆地下一个定义:为AI提供完备的客观条件(算力/带宽/数据/IP),提供AI模型(训练/推理/微调)场景,并被赋予代币经济学的项目,可以被定义为AI+DePIN。
Future Money Group将会列举以下AI+DePIN的经典范式进行梳理。

我们按照资源提供类别的不同,分成了算力、带宽、数据、其他四个板块,尝试对不同板块项目进行梳理。
2.1算力
算力端是AI+DePIN板块的主要构成,也是目前项目构成数量最多的部分。算力端项目,算力的主要构成是GPU(图形处理器)、CPU(中央处理器)和TPU(专业机器学习芯片)。其中,TPU由于制造难度高,主要由Google打造,只对外进行云算力租赁服务,因此市场规模较小。而GPU是一种与CPU类似,但更专业的硬件组件。与普通CPU相比,它可以更高效地处理并行运行的复杂数学运算。最初的GPU专用于处理游戏和动画中的图形渲染任务,不过现在它们的用途已远超于此。因此,GPU是目前算力市场的主要来源。
因此,我们能够看到的算力方面的AI+DePIN项目,很多都专长于图形和视频渲染,或者相关的游戏方面,这是由于GPU的特性导致的。
从全局看,算力类AI+DePIN产品,其算力的主要提供方由三部分构成:传统云算力服务商;闲置个人算力;自有算力。其中,云算力服务商占比较大,闲置个人算力第二。这意味着此类产品更多时候扮演着算力中介的身份。需求端则是各种AI模型开发团队。
目前这一分类中,算力几乎无法100%被运用于实际,更多时候处于闲置状态。比如Akash Network,目前处于使用状态的算力为35%左右,其余算力则处于闲置状态。io.net也是类似情况。
这可能是目前AI模型训练需求数量较少导致的,并且也是AI+DePIN能够提供廉价算力成本的原因。后续随着AI市场的扩大,这一情况将得以改善。
Akash Network:去中心化的点对点云服务市场
Akash网络是一个去中心化的点对点云服务市场,通常被称为云服务的Airbnb。Akash网络允许不同规模的用户和公司快速、稳定且经济地使用他们的服务。
与Render类似,Akash同样为用户提供了GPU部署、租赁以及AI模型训练等服务。
2023年8月,Akash上线了Supercloud,允许开发者设定他们愿意支付的价格来部署他们的AI模型,而具有额外计算能力的提供商则托管用户的模型。该功能与Airbnb非常相似,允许提供商出租未使用的容量。
通过公开竞价的方式,激励资源提供方开放其网络中的空闲计算资源,Akash Network实现了资源的更有效利用,从而为资源需求方提供了更具竞争力的价格。

目前Akash生态GPU总量为176枚GPU,但活跃数量为62枚,活跃度为35%,低于2023年9月份50%的水平。预估日收入为5000美元左右。AKT代币具有质押功能,用户通过将代币进行质押以参与网络安全的维护,获得13.15%左右的年化收益。
Akash在当前AI+DePIN板块数据表现比较优质,且7亿美元的FDV相较于Render和BitTensor,具有较大上涨空间。
Akash还接入了BitTensor的Subnet,用于扩大自身发展空间。总体而言,Akash的项目作为AI+DePIN赛道的几个优质项目之一,基本面表现优异。
io.net:接入GPU数量最多的AI+DePIN
io.net是一个去中心化计算网络,支持在Solana区块链上开发、执行和扩展ML (机器学习)应用程序,利用世界上最大的GPU集群,以允许机器学习工程师以相当于中心化服务成本的一小部分,来租用并访问分布式云服务算力。
据官方数据显示io.net拥有超过100万个处于待命状态的GPU。此外,io.net与Render的合作也扩展了可供部署的GPU资源。
io.net生态的GPU较多,但几乎都是来自于与各云计算厂商的合作和个人节点的接入,且闲置率较高,以数量最多的RTX A6000为例,8426枚GPU中,只有11%(927)枚处于使用状态,而更多型号的GPU几乎没有人使用。但目前io.net产品的一大优势在于定价便宜,相较于Akash 1.5美元一小时GPU调用成本,io.net上成本最低能做到0.1-1美元之间。

后续io.net还考虑允许IO生态的GPU提供商通过抵押原生资产的方式来提高被使用的机会。投入资产越多,被选中的机会越大。同时,质押原生资产的AI工程师同样可以使用高性能的GPU。
在GPU接入规模上,io.net是本文所列10个项目中最大的。刨除闲置率之外,处于使用状态的GPU数量也处于第一。在代币经济学方面,io.net原生代币与协议代币IO将于2024年第一季度上线,最大供应量为22,300,000枚。用户使用网络时将收取5%的费用,该费用将用于Burn IO代币或为供需双方的新用户提供激励。代币模型有着明显的拉升特性,因此io.net尽管未发币,但市场热度很大。
Golem:以CPU为主的算力市场
Golem是一个去中心化算力市场,支持任何人都可以通过创建共享资源的网络来共享和聚合计算资源。Golem为用户提供了算力租赁的场景。
Golem市场由三方组成,分别是算力供应方、算力需求方、软件开发者。算力需求方提交计算任务,Golem网络将计算任务分配给合适的算力供应方(提供RAM、硬盘空间及CPU核数等),计算任务完成之后,双方通过Token进行支付结算。

Golem主要采用CPU来进行算力堆叠,尽管在费用方面会比GPU的成本更低(Inter i9 14900k价格700美元左右,而A100 GPU价格在12000-25000美元)。但CPU无法进行高并发运算,且能耗更高。因此以CPU来进行算力租赁可能在叙事上相较于GPU项目会稍微弱一些。
Magnet AI:AI模型资产化
Magnet AI通过整合GPU算力提供商,为不同AI模型开发者提供模型训练服务。和其他AI+DePIN产品不同,Magent AI允许不同AI团队基于自身模型发布ERC-20代币,用户通过参与不同模型互动,获得不同模型代币空投和额外奖励。
2024年Q2,Magent AI将上线Polygon zkEVM & Arbrium。
与io.net有点类似,对于GPU算力都是以整合为主,并为AI团队提供模型训练服务。
不同点在于,io.net更侧重于GPU资源的整合,鼓励不同GPU集群、企业以及个人贡献GPU,同时获得回报,是算力驱动。
Magent AI看起来更侧重AI模型,由于AI模型代币的存在,可能会围绕代币、空投来完成用户的吸引和留存,并通过这种将AI模型资产化的方式来推动AI开发者的入驻。
简单概括:Magnet相当于用GPU搭建了一个集市,任何AI开发者,模型部署者都可以在上面发ERC-20代币,用户可以获取不同代币,或者主动持有不同代币。
Render:图形渲染型AI模型专业玩家
Render Network是基于去中心化GPU的渲染解决方案提供商,旨在通过区块链技术连接创作者和闲置GPU资源,以消除硬件限制,降低时间和成本,同时提供数字版权管理,进一步推动元宇宙的发展。
根据Render白皮书内容,基于Render,艺术家、工程师和开发者可以创建一系列AI应用,比如AI辅助3D内容生成、AI加速全系渲染,以及利用Render的3D场景图数据进行相关的AI模型的训练。
Render为AI开发者提供了Render Network SDK,开发者将能够利用Render的分布式GPU来执行从NeRF(神经反射场)和LightField渲染过程到生成性AI任务的AI计算任务。
根据Global Market Insights的报告,预计全球3D渲染市场规模达60亿美元。而FDV 22亿美元的Render相比仍具发展空间。
目前查询不到Render基于GPU的具体数据,但由于Render背后OTOY公司数次表现出与苹果公司的关联性;再加上业务广泛,OTOY旗下的明星渲染器OctaneRender,支持VFX、游戏、动效设计、建筑视觉化和模拟领域的所有行业领先的3D工具集,包括对于Unity3D和Unreal引擎的原生支持。
以及谷歌和微软加入了RNDR网络。Render曾在2021年处理了近25万个渲染请求,生态中的艺术家通过NFT产生了50亿美元左右的销售额。
因此,对于Render的参考估值应该对照泛渲染市场潜力(约300亿美元)。加上BME(燃烧和铸造平衡)经济模型,无论从单纯代币价格还是FDV来看,Render依旧有一定上涨空间。
Clore.ai:视频渲染
Clore.ai是一个建立在PoW基础上的提供GPU算力租用服务的平台。用户可出租自己的GPU用于AI培训、视频渲染和加密货币挖矿等任务,其他人可以以低价获取这种能力。
业务范围包括:人工智能培训、电影渲染、VPN、加密货币挖矿等。有具体算力服务需求的时候,完成网络分配的任务;如果没有算力服务需求的时候,网络找到当时挖矿收益率最高的加密货币,参与挖矿。

Clore.ai过去半年,GPU数量从2000涨到9000左右,但从GPU集成数量上来看,Clore.ai超过Akash。但其二级市场FDV只有Akash的20%左右。
代币模型上,CLORE采用POW挖矿模式,没有预挖和ICO,每个区块的50%分配给矿工,40%分配给出租者,10%分配给团队。
代币总量13亿枚,自2022年6月开始挖矿,至2042年基本进入全流通,当前流通量大约为2.2亿枚。2023年底流通量约为2.5亿枚,占代币总量的20%。所以当前实际FDV为3100万美元,理论上,Clore.ai处于严重被低估状态,但由于其代币经济学上,矿工分配比例50%,挖卖提比例过高,因此币价提升具有较大阻力。
Livepeer:视频渲染、推理
Livepeer是基于以太坊的去中心化视频协议,向以合理价格安全地处理视频内容的各方发放奖励。
据官方称,Livepeer每周有数千个GPU资源进行数百万分钟的视频转码。
Livepeer或将采用“主网”+“子网”的方式,让不同的节点运营商生成子网,通过在 Livepeer 主网上兑现付款来执行这些任务。比如,引入AI视频子网用于专门进行视频渲染领域的AI模型训练。
Livepeer此后会将与AI有关的部分从单纯的模型训练扩列至推理 & 微调。
Aethir:专注于云游戏和AI
Aethir是一个云游戏平台,专为游戏和人工智能公司构建的去中心化云基础设施 (DCI)。它有助于代替玩家交付繁重的GPU计算负载,确保游戏玩家在任何地方、任何设备上都能获得超低延迟的体验。
同时,Aethir提供包括GPU、CPU、磁盘等要素的部署服务。2023年9月27日,Aethir正式为全球客户提供云游戏和AI算力的商用服务,通过集成去中心化算力的方式来为自身平台的游戏以及AI模型提供算力支持。
云游戏通过将计算渲染的算力需求转移到云端,消除了终端设备的硬件及操作系统的限制,显著扩大了潜在的玩家基础规模。
2.2 带宽
带宽是DePIN向AI提供的资源中的一种,2021年全球带宽市场规模超过500亿美元,预测2027年将突破千亿。
由于AI模型的越来越多以及更复杂,模型训练通常采用多种并行计算策略,例如数据并行、流水线并行和张量并行等。在这些并行计算模式下,多台计算设备间集体通信操作的重要性日益凸显。因此,在构建大型AI模型的大规模训练集群时,网络带宽的作用就凸显了出来。
更重要的是,一个稳定且足够可靠的带宽资源,能够确保不同节点之间同时相应,技术上避免了单点控制的出现(比如Falcon采用低延迟+高带宽的中继网络模式来寻求延迟与带宽之间需求的平衡),最终确保整个网络的可信任和抗审查。
Grass:兼容移动端的带宽挖矿产品
Grass是Wynd Network的旗舰产品, Wynd专注于开放⽹络数据,于2023年融资100万美元。Grass允许⽤户通过出售未使⽤的⽹络资源来通过互联⽹连接来获得被动收⼊。
用户可以在Grass上出售互联网带宽,为有需要的AI开发团队提供带宽服务,帮助AI模型训练,从而获得代币回报。
目前,Grass即将推出移动端版本,由于移动端与PC端具有不同的IP地址,这意味着Grass的用户将为平台同时提供更多的IP地址,而Grass将收集到更多的IP地址从而为AI模型训练提供更好的数据效率。
目前Grass有两种IP地址提供方式:PC端下载拓展程序,以及移动端APP下载。(PC端与移动端需处于不同网络)
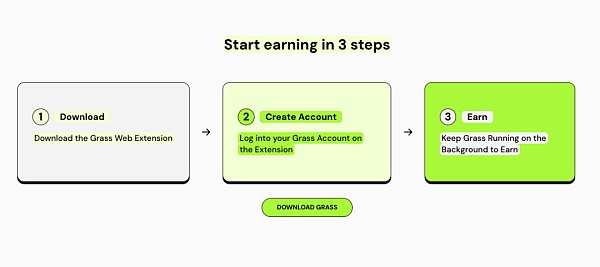
截至2023年11月29日,Grass平台已经拥有103,000次下载和1,450,000个唯一IP地址。
移动端和PC端对AI的需求度不一样,因此适用的AI模型训练类别有所不同。
比如,移动端对于图片优化、人脸识别、实时翻译、语音助手、设备性能优化等方面拥有大量数据。这些是PC端难以提供的。
目前Grass在移动端AI模型训练上处于比较先发的身位。考虑到当前全球范围内,移动端市场的巨大潜力,Grass的前景值得关注。
但目前Grass尚未在AI模型方面提供更有效的信息,推测前期可能单纯以矿币为主要运营方式。
Meson Network:Layer 2 兼容移动端
Meson Network是基于区块链Layer 2的下一代存储加速网络,通过挖矿的形式聚合闲置服务器,调度带宽资源并将其服务于文件以及流媒体加速市场,包含传统网站、视频、直播及区块链存储方案。
我们可以将Meson Network理解为一个带宽资源池,池子两边可以看作是供需双方。前者贡献带宽,后者使用带宽。
在Meson具体的产品结构中,有2个产品(GatewayX、GaGaNode)在负责接收全球不同节点贡献的带宽,1个产品(IPCola)则负责将这些汇聚的带宽资源进行变现。
GatewayX:以集成商业闲置带宽为主,主要瞄准IDC中心。
从Meson的数据看板可以发现,目前接入的IDC在全世界范围内共有2万多个节点,并且形成了12.5Tib/s的数据传输能力。
GaGaNode:主要整合住宅及个人设备闲置带宽,提供边缘计算辅助。
IPCola:Meson变现渠道,进行IP和带宽分配等任务。

目前Meson透露,半年收入在百万美金以上。据官网统计,Meson有IDC节点27116个,IDC容量17.7TB/s。
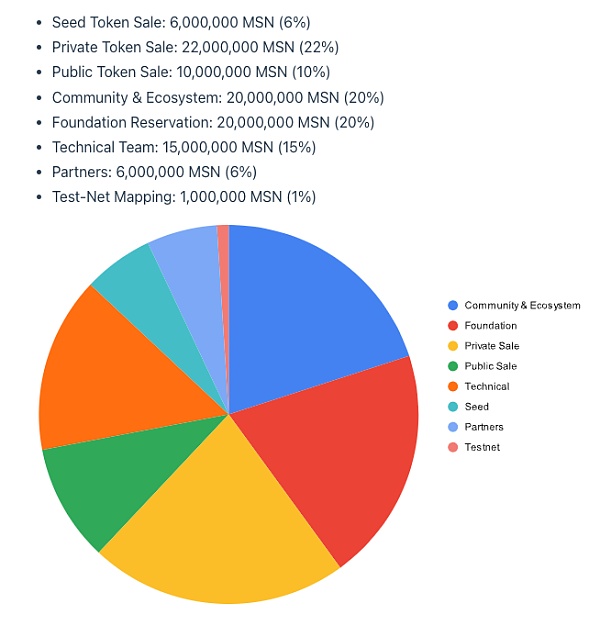
目前Meson预计2024年3-4月份发行代币,但公布了代币经济学。
代币名称:MSN,初始供应量1亿枚,第一年挖矿通胀率为5%,每年下降0.5%。
Network 3:与Sei网络集成
Network3是一家AI公司,构建了一个专门的AI Layer 2,并与Sei集成。通过AI模型算法优化和压缩,边缘计算和隱私计算,为全球范围内的AI开发者提供服务,帮助开发者快速、便捷、高效地大規模训练和验证模型。
据官网数据,目前Network3已经有超过58000个活跃节点,提供2PB的带宽服务。与Alchemy Pay、ETHSign、IoTeX等10个区块链生态达成合作。
2.3 数据
与算力和带宽不同,数据端供应目前市场较为小众。并且具有鲜明的专业性。需求群体通常是项目自身或者相关品类的AI模型开发团队。比如Hivemapper。
通过自身数据喂养训练自己的地图模型,这一范式在逻辑上并不存在难点,因此我们可以尝试将视野放宽到与Hivemapper类似的DePIN项目中,比如DIMO、Natix和FrodoBots。
Hivemapper:专注于自身Map AI产品赋能
HiveMapper是Solana上DePIN概念Top之一,致力于创建一个去中心化的”谷歌地图“。用户通过购买HiveMapper推出的行车记录仪,通过使用并与HiveMapper共享实时影像,便能获得HONEY代币。
关于Hivemapper,Future Money Group曾在《FMG 研报:30天上涨19倍,读懂以Hivemapper为代表的汽车类DePIN业态》中有详细描述,在此不做展开。之所以把Hivemapper列入AI+DePIN板块,是因为Hivemapper推出了MAP AI,是一个AI地图制作引擎,可以基于行车记录仪所采集的数据生成高质量地图数据。
Map AI设置了一个新角色,AI训练师。该角色该角色囊括了此前的行车记录仪数据贡献者,以及Map AI模型训练师。
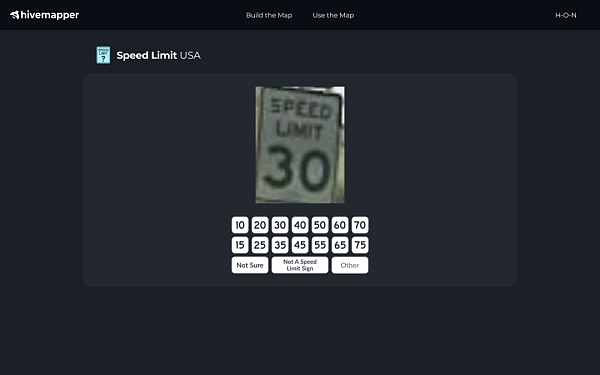
Hivemapper对于AI模型训练师的要求并没有刻意专业化,反而采用了类似远程任务、猜地理位置等类似游戏行为的低参与门槛,让更多的IP地址参与进来。DePIN项目的IP资源越丰富,AI获取数据的效率就更高。而参与AI训练的用户,同样也能获得HONEY代币的奖励。
AI在Hivemapper中的应用场景较为小众,Hivemapper也并不支持第三方模型训练,Map AI目的在于优化自身地图产品。因此对Hivemapper的投资逻辑不会产生改变。
Potential
DIMO:对汽车内部数据进行采集
DIMO是一个建立在Polygon上的汽车物联网平台,使驾驶员能够收集和共享他们的车辆数据,记录的数据包括汽车行驶公里、行驶速度、位置追踪、轮胎压力、电池/发动机健康状况等。
通过分析车辆数据,DIMO平台可以预测何时需要维护并及时提醒用户。驾驶员不仅能深入了解自己的车辆,还能将数据贡献给DIMO的生态系统,从而可以获得DIMO代币作为奖励。而作为数据消费方可以从协议中提取数据以了解电池、自动驾驶系统和控件等组件的性能。
Natix:隐私赋能地图数据收集
Natix是一个利用AI隐私专利打造的去中心化网络。旨在基于AI隐私专利,将全球与摄像头设备(智能手机、无人机、汽车)进行结合,创建中保摄像头网络,同时在隐私合规性的前提下收集数据,并对去中心化动态地图(DDMap)进行内容填充。
参与数据提供的用户可以获得代币和NFT进行激励。
FrodoBots:机器人为载体的去中心化网络应用
FrodoBots是一个以移动机器人为载体,通过摄像头采集影响数据,具有一定社交属性的DePIN类游戏。
用户通过购买机器人来参与到游戏过程中,与全球玩家进行交互。同时机器人自带的摄像头也会对道路和地图数据进行采集汇总。
以上三个项目,都具有数据采集和IP提供两个要素,尽管他们尚未进行相关的AI模型训练,但都为AI模型的引入提供了必要条件。这些项目包括Hivemapper在内,都是需要通过摄像头来采集数据,并形成完备的图谱。因此适配的AI模型也都局限于以地图构建为主的领域。AI模型的赋能,将能够帮助帮助项目建立更高的护城河。
需要注意的点在于,通过摄像头采集往往会遇到双向的隐私侵犯等法规问题:比如外置摄像头采集外部影像对于路人肖像权的定义;以及用户对自身隐私的重视。比如Natix运营AI来进行隐私保护。
2.4 算法
算力、带宽、数据侧重于资源端的区分,而算法则侧重于AI模型方面。本文以BitTensor为例,BitTensor既直接不贡献数据,也不直接贡献算力,而是通过区块链网络和激励机制,来对不同的算法进行调度和筛选,从而让AI领域形成一个自由竞争、知识共享的模型市场。
类似OpenAI,BitTensor目的在于在维持模型去中心化特性的同时,以达到与传统模型巨头相匹配的推理性能。
算法赛道具有一定超前性,类似的项目并不多见。当AI模型,尤其是基于Web3诞生的AI模型涌现,模型之间的竞争就将成为常态化。
同时,模型之间的竞争也会让AI模型产业的下游:推理、微调的重要性提高。AI模型训练只是AI产业的上游,一个模型需要先经过训练,具备初始的智能性,并在此基础上对模型进行更仔细的模型推理和调整(可以理解为优化),最终才能作为一个成品来进行边缘部署。这这些过程需要更复杂的生态架构和算力支撑。也意味着潜在的发展潜力巨大。
BitTensor:AI模型预言机
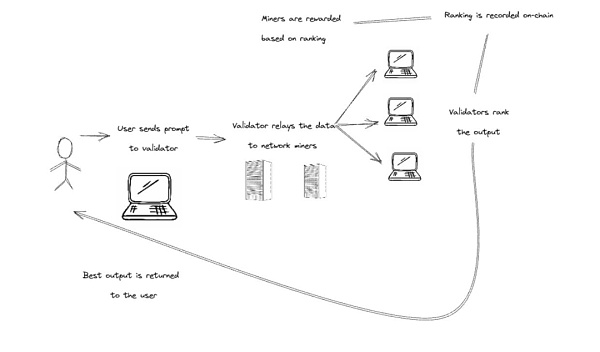
BitTensor是一个架构类似Polkadot主网+子网的去中心化机器学习生态。
工作逻辑:子网将活动信息传给Bittensor API(角色类似预言机),然后API会将有用信息传给主网,主网再分发Rewards。
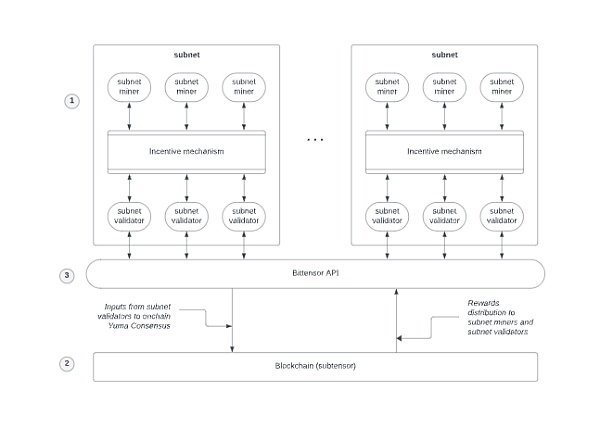

BitTensor 32个子网
BitTensor生态内角色:
矿工:可以理解为全世界各种AI算法和模型的提供方,它们托管AI模型并将其提供给Bittensor网络;不同类型的模型组成了不同的子网。
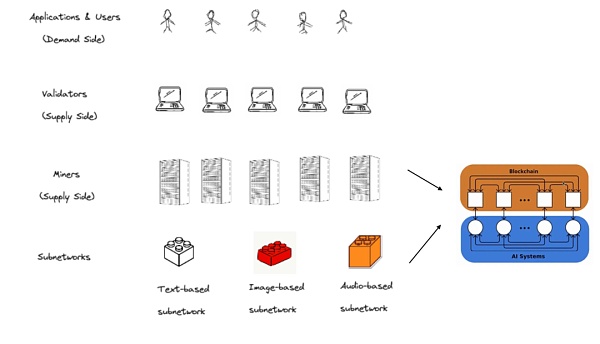
验证者:Bittensor网络内的评估者。评估AI模型的质量和有效性,根据特定任务的性能对AI模型进行排名,帮助消费者找到最佳解决方案。
用户:Bittensor提供的AI模型最终使用方。可以是个人,也可以是谋求AI模型来做应用的开发者们。
提名人:将代币委托给特定验证者来表示支持,也可以换不同的验证者来委托。
开放的AI供需链条 :有人提供不同模型,有人评价不同模型,有人使用最好的模型所提供的结果。
和Akash、Render这种类似“算力中介”的角色不同,BitTensor更像一个“劳务市场”,用已有模型去吸收更多数据以此来让模型更加合理。矿工和验证者更像“施工方”和“监工”的角色。用户提出问题,矿工们输出答案,验证者再来评估答案的质量,最终返回给用户。
BitTensor代币为TAO。TAO的市值目前仅次于RNDR,但由于4年减半的长期释放机制存在,市值与完全稀释价值的比率反而是几个项目中最低的,也意味着TAO的总体流通量目前来看相对较低,但单价较高。因此意味着TAO的实际价值处于低估状态。
目前比较难以寻找合适估值标的,如果从架构相似性出发,Polkadot(约120亿美元)为参照对象,TAO有接近8倍的上涨空间。
如果按照“预言机”属性出发,Chainlink(140亿美元)为参照对象,TAO有接近9倍的涨幅。
如果以业务相似性出发,OpenAI(从微软获得约300亿美元)为参照,TAO的上涨硬顶可能在20倍左右。
结论
总体而言,AI+DePIN推动了Web3语境下AI赛道的范式转移,让市场从“AI能在Web3里做什么?”的固有思维中跳出,去思考“AI和Web3能为世界带来什么?”这一更大的问题。
如果说英伟达CEO黄仁勋将生成式大模型的发布称为AI的 “iPhone” 时刻,那么AI与DePIN的结合便意味着Web3真正迎来“iphone”时刻。
DePIN作为Web3在现实世界最容易被接受以及最成熟的用例,正在让Web3变的更加可被接受。
由于AI+DePIN项目中IP节点与Web3玩家的部分重合性,二者的结合,同时也在帮助行业催生属于Web3自己的模型和AI产品。这将有利于Web3行业的整体发展,并且为行业去开拓新的赛道,比如AI模型的推理和微调、以及移动端AI模型发展等。
一个有趣的点在于,文中所罗列的AI+DePIN的产品,似乎可以去嵌套公链的发展路径。在此前的周期中,各种新公链涌现,用自身的TPS和治理方式来吸引各种开发者的入驻。
当前的AI+DePIN产品也是这样,基于自身的算力、带宽、数据以及IP优势来吸引各种AI模型开发者入驻。所以,我们目前看到AI+DePIN产品有偏向同质化竞争的趋势。
问题的关键并不在于算力的多少(尽管这是个很重要的先决条件),而在于如何去运用这些算力。现在的AI+DePIN赛道仍旧处于“野蛮生长”的早期,因此我们对于AI+DePIN的未来格局以及产品形式,可以抱有一个充满期待的预期。
参考文献
1.https://www.techopedia.com/decentralized-physical-infrastructure-networks-DePIN-brings-ai-and-crypto-together
2.https://medium.com/meson-network/with-the-increasing-ai-and-DePIN-trends-why-should-you-consider-keeping-an-eye-on-meson-network-59094665c9bd
3.https://medium.com/cudos/the-rise-of-DePIN-unveiling-the-future-of-ai-and-metaverse-compute-requirements-213f7b5b1171
4.https://www.numenta.com/blog/2022/05/24/ai-is-harming-our-planet/
5.https://www.techflowpost.com/article/detail_15398.html
6.https://www.numenta.com/blog/2022/05/24/ai-is-harming-our-planet/
7.https://mirror.xyz/livepeer.eth/7yjb5osZ28AJ9xvA54bZ4T2hUpNM5O9rrpv-zmGWDZ4
The competition of products in the era is inseparable from the computing power data at the resource end, especially the stable resource end to support the model training iteration, and at the same time, it needs huge user targets to help feed the data, which can qualitatively change the efficiency of the model, and can help small and medium-sized start-up teams to realize overtaking the traditional giants in corners, determine the lower limit of the ecological computing power bandwidth and other resources, and simply integrate computing power without the moat model's application depth optimization, specialization and effective use of data to determine the project. In the limited context, fine-tuning model reasoning and mobile model market will be paid attention to. There are three problems in market analysis: data statistics. From the eve of the birth of, to, global products have generated more than 100 million visits, and the average monthly growth rate is 100 million times. Behind the prosperity of products is the increasing dependence on computing power. A paper from the University of Massachusetts at Amherst pointed out that training an artificial intelligence model is equivalent to the carbon emissions of five cars in its lifetime. However, this analysis only involves. Once training, when the model is improved through repeated training, the use of energy will greatly increase. The latest language model contains billions or even trillions of weights. A popular model has hundreds of millions of machine learning parameters. If it takes one day and ten thousand dollars to train the model, the product competition in the era has gradually expanded into a resource-based war dominated by computing power, which extends to three questions: does the first product have enough computing power bandwidth at the resource end, especially the stable resource end to support it? In the traditional field, due to the gap of chip demand end and the world wall based on policy ideology, chip manufacturers are naturally in an advantageous position and can greatly drive up the price. For example, the model chip has risen from $10,000 in January to $10,000, which further increases the cost of the model training team. The second problem is that the satisfaction of resource-side conditions helps the project solve the hardware demand, but the model training iteration also needs huge user targets to help. After the scale of the busy feeding data model exceeds a certain threshold, the performance of different tasks shows a breakthrough growth. The third problem is that it is difficult for small and medium-sized start-up teams to overtake in corners. The monopoly of computing power in the traditional financial market also leads to the monopoly of model schemes. Large model manufacturers represented by equality are further building their own moats, and small and medium-sized teams need to seek more differentiated competition. In fact, the above three problems can be found from it for a long time. The ecology is more prosperous. The following picture shows the solution of some track projects of the produced ecology, which is the abbreviation of decentralized physical infrastructure network and the collection of production relations between people and equipment. Through the combination of token economics and hardware equipment such as computer car cameras, users and equipment are organically combined, and the orderly operation of the economic model is realized. Compared with the broader definition, nature and hardware equipment are more closely related to traditional enterprises, so they are attracting off-site teams and phases. There is a natural advantage in terms of funds. The pursuit of distributed computing power by ecology and the encouragement of contributors just solve the demand of products for computing power sum. Token economics is used to promote the entry of idle personal computing power in the world computing power center, which reduces the risk of computing power centralization and the cost of team calling computing power. The huge and diversified composition of ecology helps the model to realize the diversity and objectivity of data acquisition channels, and enough data providers can also ensure the improvement of model performance. The overlapping of ecological users and users in portraits can help settled projects develop more distinctive models and form differentiated competition, which is not available in the traditional market. The data collection of in-field models usually comes from public data sets or is collected by model makers themselves, which will be limited by cultural background and region, making the content of model output subjective and distorted. The traditional data collection method is limited by collection efficiency and cost, and it is difficult to obtain a larger number of model scale parameters and training time. And data quality. For the model, the larger the scale of the model, the more likely the performance of the model will lead to qualitative change. It has a natural advantage in this field. For example, nearly 10,000 contributors are providing the map model with the combination of data and data, which also means that the integration of data and data has risen to a new height. At present, the current projects have widely erupted in the application side and have hardly got rid of the direct dependence on the infrastructure. The existing models relying on the traditional computing platform will be implanted into the project to create the model. Then few elements have been involved in the lower reaches of the food chain and can't get real excess returns. For distributed computing platforms, simple computing power can't really tap the potential of both. In this relationship, computing power providers can't get more excess profits and the ecological structure is too simple, so they can't make the flywheel run through token economics. However, the concept is breaking this inherent relationship and shifting their attention to a broader model. Much-needed equipment computing bandwidth algorithm data user model training data provider and ecological incentive mechanism token economics. We can boldly define a project that provides a complete objective condition computing bandwidth data, provides a model training reasoning fine-tuning scenario and is endowed with token economics. It can be defined as combing the following classic paradigms. We divide it into computing bandwidth data according to the different types of resources provided, and the other four sections try to comb different plate projects. The computing power is the main component of the plate, and it is also the part with the largest number of projects at present. The computing power of the computing power is mainly composed of graphics processor, central processing unit and professional machine learning chip. Because of the high manufacturing difficulty, the market scale is small, but it is a similar but more professional hardware component. Compared with ordinary ones, it can handle complex mathematical operations running in parallel more efficiently. It was originally dedicated to dealing with games and animations. Graphics rendering tasks, however, are now used far beyond this, so they are the main source of computing power market at present. Therefore, many computing power projects we can see are specialized in graphics and video rendering or related games. This is due to the characteristics of. From a global perspective, the main providers of computing power products consist of three parts, of which the traditional cloud computing power service providers have their own computing power, among which the cloud computing power service providers account for a relatively large number of idle individuals. Second, this means that the demand side of such products is more often the computing power intermediary of various model development teams. 比特币今日价格行情网_okx交易所app_永续合约_比特币怎么买卖交易_虚拟币交易所平台
注册有任何问题请添加 微信:MVIP619 拉你进入群

打开微信扫一扫
添加客服
进入交流群
1.本站遵循行业规范,任何转载的稿件都会明确标注作者和来源;2.本站的原创文章,请转载时务必注明文章作者和来源,不尊重原创的行为我们将追究责任;3.作者投稿可能会经我们编辑修改或补充。