谷歌反击:Project Astra正面硬刚GPT-4o Veo对抗Sora



来源:机器之心
机器之心编辑部
Laiyuan machine zhixin machine zhixin editorial department 比特币今日价格行情网_okx交易所app_永续合约_比特币怎么买卖交易_虚拟币交易所平台
通用的 AI,能够真正日常用的 AI,不做成这样现在都不好意思开发布会了。
5 月 15 日凌晨,一年一度的「科技界春晚」Google I/O 开发者大会正式开幕。长达 110 分钟的主 Keynote 提到了几次人工智能?谷歌自己统计了一下:

是的,每一分钟都在讲 AI。
生成式 AI 的竞争,最近又达到了新的高潮,本次 I/O 大会的内容自然全面围绕人工智能展开。
「一年前在这个舞台上,我们首次分享了原生多模态大模型 Gemini 的计划。它标志着新一代的 I/O,」谷歌首席执行官桑达尔・皮查伊(Sundar Pichai)说道。「今天,我们希望每个人都能从 Gemini 的技术中受益。这些突破性的功能将进入搜索、图片、生产力工具、安卓系统等方方面面。」
24 小时以前,OpenAI 故意抢先发布 GPT-4o,通过实时的语音、视频和文本交互震撼了全世界。今天,谷歌展示的 Project Astra 和 Veo,直接对标了目前 OpenAI 领先的 GPT-4o 与 Sora。
这是 Project Astra 原型的实时拍摄:
我们正在见证最高端的商战,以最朴实的方式进行着。
最新版 Gemini 革新谷歌生态
在 I/O 大会上,谷歌展示了最新版 Gemini 加持的搜索能力。
25 年前,谷歌通过搜索引擎推动了第一波信息时代的浪潮。现在,随着生成式 AI 技术的演进,搜索引擎可以更好地帮你回答问题,它可以更好地利用上下文内容、位置感知和实时信息能力。
基于最新版本的定制化 Gemini 大模型,你可以对搜索引擎提出任何你想到的事情,或任何需要完成的事 —— 从研究到计划到想象,谷歌将负责所有工作。
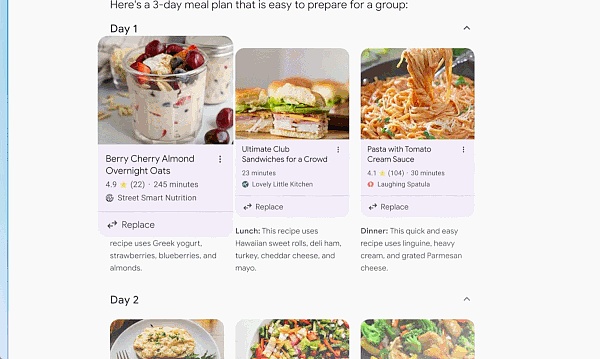
有时你想要快速得到答案,但没有时间将所有信息拼凑在一起。这个时候,搜索引擎将通过 AI 概述为你完成工作。通过人工智能概述,AI 可以自动访问大量网站来提供一个复杂问题的答案。
借助定制 Gemini 的多步推理功能,AI 概述将有助于解决日益复杂的问题。你无需再将问题分解为多个搜索,现在可以一次性提出最复杂的问题,以及你想到的所有细微差别和注意事项。
除了为复杂问题找到正确的答案或信息之外,搜索引擎还可以与你一起,一步步制定计划。
在 I/O 大会上,谷歌重点强调了大模型的多模态和长文本能力。技术的进步为 Google Workspace 等生产力工具变得更加智能化。
例如,现在我们可以要求 Gemini 总结一下学校最近发来的所有电子邮件。它会在后台识别相关的 Email,甚至分析 PDF 等附件。随后你就能获得其中的要点和行动项目的摘要。

Gemini 进行了一些升级和改进,为机器学习和 API 功能提供了预览版。
使用 API 的开发人员和 Google Cloud 客户可以在 1.5 Pro 中获得 200 万 token 上下文窗口。

为了完成开发工作,1.5 Pro 具备优化的多任务学习能力,使其能够更轻松地管理开放 API,并提供包含长文档及政策、法规内容的多通道输入功能。这使得 Gemini 1.5 Pro 版本成为了机器学习和 API 的预览版。
多模态 Gemini 1.5 Pro 版实现了如文本输入到文字摘要、文旦和图像到文本等多种功能,为开发者和机构提供了更多可能性,帮助其开发自己的大规模 AI 项目。
用户不仅能够看到 AI 技术能力的增强。越来越多的机构正在部署基于 Gemini 内部测试版的应用。
Gemini 家族的更新,为用户和开发者们带来了更多便捷和高效的功能,而对于 Google 而言,这也是对其长期投入的 k AI 技术的一次验证。
谷歌发布Gemini 1.5 Pro和新一代开源大模型Gemma 2
Gemini 1.5 Pro 上下文窗口扩展到 200 万 token
谷歌宣布,Gemini模型已经吸引了超过150万开发者,其产品用户已经超过20亿。
在过去几个月中,谷歌不仅将Gemini 1.5 Pro的上下文窗口扩展到200万token,还通过数据和算法改进了其代码生成、逻辑推理和规划、多轮对话以及音频和图像理解能力。

现在,Gemini 1.5 Pro能够遵循日益复杂和细致的指令,包括涉及角色、格式和风格的产品级行为指令。此外,用户还可以通过设置系统指令来引导模型行为。
谷歌还在Gemini API和Google AI Studio中添加了音频理解功能,使Gemini 1.5 Pro能够推理Google AI Studio中上传的视频图像和音频。此外,谷歌还将Gemini 1.5 Pro集成到了Google的产品中,包括Gemini Advanced和Workspace应用程序。
Gemini 1.5 Pro的定价为每100万token 3.5美元。
其中,Gemini最令人兴奋的转变之一是Google搜索。
在过去一年中,作为搜索生成体验的一部分,Google搜索回答了数十亿个查询。现在,人们可以以全新的方式使用它进行搜索,提出新类型的问题、更长、更复杂的查询,甚至使用照片进行搜索,并获得网络所提供的最佳信息。

谷歌即将推出Ask Photos功能。以Google Photos为例,该功能大约在九年前推出。如今,用户每天上传的照片和视频数量超过60亿张。人们喜欢使用照片来搜索他们的生活。Gemini让这一切变得更加容易。
例如,当你在停车场付款但忘记了自己的车牌号码时,以前你可能需要在照片中搜索关键字,然后浏览多年的照片,寻找车牌。现在,你只需询问照片即可。

再比如,你想回忆女儿露西娅的早期生活。现在,你可以问照片:露西娅什么时候学会游泳的?你甚至可以追问更复杂的事情:告诉我露西娅的游泳进展如何。
在这一切中,Gemini超越了简单的搜索,识别了不同的背景,包括游泳池、大海等不同场景,然后将所有内容汇总在一起,以便用户查看。谷歌将于今年夏天推出Ask Photos功能,并计划推出更多功能。


新一代开源大模型Gemma 2
今天,谷歌还发布了开源大模型Gemma的一系列更新,其中包括全新架构的Gemma 2。
据介绍,Gemma 2旨在实现突破性的性能和效率,新开源模型参数为27B。

![]()
近日,Gemma 家族迎来了新的成员,随着 PaliGemma 的扩展,家族版图也随之扩展。PaliGemma 是谷歌根据 PaLI-3 模型启发而开发的首个视觉语言模型。
通用 AI 智能体 Project Astra
长久以来,智能体一直是 Google DeepMind 着重研究的领域。
就在昨天,我们目睹了 OpenAI 推出的 GPT-4o,其令人震撼的实时语音、视频交互能力给人留下深刻印象。
而今天,Google DeepMind 推出的视觉与语音交互通用 AI 智能体项目 Project Astra 隆重亮相,这标志着 Google DeepMind 对未来 AI 助手的雄心展望。
谷歌表示,为了实现真正的人机交互,智能体需要像人类一样理解和应对复杂、动态的现实世界,也需要吸收并记住所见所闻,以了解上下文并采取行动。此外,智能体还应具备主动性、可教性和个性化,以便用户能够自然地与之交流,无延迟、无滞后。
近几年来,谷歌一直致力于提升模型的感知、推理和对话方式,以使交互更加自然、速度更快、质量更高。
在今天的主题演讲中,Google DeepMind 展示了 Project Astra 的交互能力:
据介绍,谷歌在 Gemini 的基础上打造了智能体原型,它能够通过连续编码视频帧、将视频和语音输入整合到事件时间线中并缓存此信息,以实现更快的信息处理。
通过语音模型,谷歌还进一步加强了智能体的发音,为其提供了更广泛的语调。这些智能体能够更好地理解所处的语境,并迅速做出响应。
就此,我们简要评论一下。机器之心认为,与 GPT-4o 实时演示相比,Project Astra 项目发布的 Demo 在交互体验上稍显不足。无论是响应时长、语音情感的丰富性还是可打断性等方面,GPT-4o 的交互体验似乎更加自然。读者们又有何看法呢?
反击 Sora:发布视频生成模型 Veo
在 AI 视频生成领域,谷歌宣布推出视频生成模型 Veo。Veo 能够生成各种风格的高质量 1080p 分辨率视频,时长超过一分钟。
凭借对自然语言和视觉语义的深入理解,Veo 模型在理解视频内容、渲染高清图像、模拟物理原理等方面都取得了突破。Veo 生成的视频能够准确、细致地表达用户的创作意图。
例如,输入以下文本 prompt:
Many spotted jellyfish pulsating under water. Their bodies are transparent and glowing in deep ocean.
(许多斑点水母在水下搏动。它们的身体透明,在深海中闪闪发光。)
再比如生成人物视频,输入 prompt:
A lone cowboy rides his horse across an open plain at beautiful sunset, soft light, warm colors.
(在美丽的日落、柔和的光线、温暖的色彩下,一个孤独的牛仔骑着马穿过开阔的平原。)
或者是近景人物视频,输入 prompt:
``````htmlA woman sitting alone in a dimly lit cafe, a half-finished novel open in front of her. Film noir aesthetic, mysterious atmosphere. Black and white.
Google Introduces Veo, Imagen 3, and Trillium at Google I/O
Google has unveiled a trio of groundbreaking advancements at the Google I/O conference, showcasing their commitment to advancing creative and technological innovation.
Veo: Revolutionizing Video Generation
In a breakthrough for video creation, Google introduces Veo, a model capable of unprecedented creative control and understanding of film terminology, resulting in seamless and realistic videos.
For instance, with Veo, filmmakers can effortlessly capture stunning aerial shots along the Hawaii coastline on a sunny day, simply by inputting a prompt:
Drone shot along the Hawaii jungle coastline, sunny day
Veo also supports generating videos using both images and text prompts, ensuring the video aligns with the style of the provided reference image and textual description.
Interestingly, Google's demo showcases a video of a llama created by Veo, reminiscent of Meta's Llama, an open-source model.

With Veo, creators can produce videos lasting up to 60 seconds or longer. This capability is crucial for applying video generation models in filmmaking, whether through a single prompt or a series of prompts telling a story.
Veo builds upon Google's visual content generation work, leveraging models like Generative Query Network (GQN), DVD-GAN, Imagen-Video, Phenaki, WALT, VideoPoet, and Lumiere.
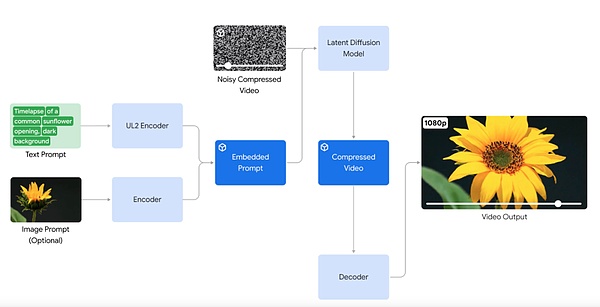
Starting today, Google will provide a preview version of Veo to select creators for use in VideoFX, with plans to integrate some of Veo's features into products like YouTube Shorts.
Imagen 3: Advancements in Text-to-Image Generation
Continuing its series of model upgrades, Google unveils Imagen 3, enhancing details, lighting, noise, and significantly improving its understanding of prompts.
To capture finer details from longer prompts, such as specific camera angles or compositions, Google enriches each image's title in the training data with more descriptive information.
For example, by adding details like "slightly blurred foreground" and "warm lighting" to the input prompt, Imagen 3 can generate images accordingly:

Furthermore, Google addresses the issue of text blurriness in generated images by optimizing image rendering, ensuring that text in the generated images is clear and stylized.

Imagen 3 will offer multiple versions optimized for different types of tasks to enhance usability.
Starting today, Google will provide a preview version of Imagen 3 to select creators for use in ImageFX, with users able to join the waitlist.
Trillium: The Next Generation TPU Chip
As generative AI continues to reshape human-technology interactions, Google unveils the sixth-generation TPU, Trillium, the most powerful and energy-efficient TPU to date, set to launch by the end of 2024.
Trillium TPU, highly customized for AI applications, powers several innovations announced at the Google I/O conference, including Gemini 1.5 Flash, Imagen 3, and Gemma 2, all trained and serviced using TPUs.

Compared to TPU v5e, Trillium TPU boasts a four-fold increase in peak chip-level compute performance, providing the computational, memory, and communication capabilities necessary for training and fine-tuning the most powerful models.
``````html谷歌在最新的发布会上宣布,他们的最新一代人工智能处理器 Trillium 已经问世。据悉,Trillium 不仅将性能提升了 7 倍,还将高带宽内存(HBM)以及芯片间互连(ICI)带宽翻了一番。此外,Trillium 还配备了第三代 SparseCore,专门用于处理高级排名和推荐工作负载中常见的超大型嵌入。
据谷歌表示,Trillium 能够以更快的速度训练新一代 AI 模型,同时减少延迟和降低成本。此外,Trillium 还被称为迄今为止谷歌最具可持续性的 TPU,与其前代产品相比,能效提高了超过 67%。
Trillium 单个高带宽、低延迟的计算集群(pod)中最多可扩展到 256 个 TPU(张量处理单元)。除了这种集群级别的扩展能力之外,通过多片技术(multislice technology)和智能处理单元(Titanium Intelligence Processing Units,IPUs),Trillium TPU 还可以扩展到数百个集群,连接成千上万的芯片,形成一个由每秒数 PB(multi-petabit-per-second)数据中心网络互联的超级计算机。
谷歌早在 2013 年就推出了首款 TPU v1,随后在 2017 年推出了云 TPU,这些 TPU 一直在为实时语音搜索、照片对象识别、语言翻译等各种服务提供支持,甚至为自动驾驶汽车公司 Nuro 等产品提供技术动力。
Trillium 也是谷歌 AI Hypercomputer 的一部分,这是一种开创性的超级计算架构,专为处理尖端的 AI 工作负载而设计。谷歌正在与 Hugging Face 合作,优化开源模型训练和服务的硬件。

以上,就是今天谷歌 I/O 大会的所有重点内容了。可以看出,谷歌在大模型技术与产品方面与 OpenAI 展开了全面竞争的态势。而通过这两天 OpenAI 与谷歌的发布,我们也能发现大模型竞争进入了到了一个新的阶段:多模态、更自然地交互体验成为了大模型技术产品化并为更多人所接受的关键。
期待 2024 年,大模型技术与产品创新,能为我们带来更多的惊喜。
注册有任何问题请添加 微信:MVIP619 拉你进入群

打开微信扫一扫
添加客服
进入交流群
1.本站遵循行业规范,任何转载的稿件都会明确标注作者和来源;2.本站的原创文章,请转载时务必注明文章作者和来源,不尊重原创的行为我们将追究责任;3.作者投稿可能会经我们编辑修改或补充。