
NEAR:为何AI需要Web3?Web3究竟会给AI带来什么样的颠覆式进步



Why AI Needs to be Open
让我们来探讨一下“为什么人工智能需要开放”。我的背景是Machine Learning,在我的职业生涯中大约有十年的时间一直在从事各种机器学习的工作。但在涉足Crypto、自然语言理解和创立NEAR之前,我曾在谷歌工作。我们现在开发了驱动大部分现代人工智能的框架,名为Transformer。离开谷歌之后,我开始了一家Machine Learning公司,以便我们能够教会机器编程,从而改变我们如何与计算机互动。但我们没有在2017或者18年这样做,那时候太早了,当时也没有计算能力和数据来做到这一点。

我们当时所做的是吸引世界各地的人们为我们做标注数据的工作,大多数是学生。他们在中国、亚洲和东欧。其中许多人在这些国家没有银行账户。美国不太愿意轻易汇款,所以我们开始想要使用区块链作为我们问题的解决方案。我们希望以一种程序化的方式向全球的人们支付,无论他们身在何处,都能让这变得更加容易。顺便说一句,Crypto的目前挑战是,现在虽然NEAR解决了很多问题,但通常情况下,你需要先购买一些Crypto,才能在区块链上进行交易来赚取,这个过程反其道而行了。
就像企业一样,他们会说,嘿,首先,你需要购买一些公司的股权才能使用它。这是我们NEAR正在解决的很多问题之一。现在让我们稍微深入讨论一下人工智能方面。语言模型并不是什么新鲜事物,50年代就存在了。它是一种在自然语言工具中被广泛使用的统计工具。很长一段时间以来,从2013年开始,随着深度学习重新被重新启动,一种新的创新就开始了。这种创新是你可以匹��单词,新增到多维度的向量中并转换为数学形式。这与深度学习模型配合得很好,它们只是大量的矩阵乘法和激活函数。

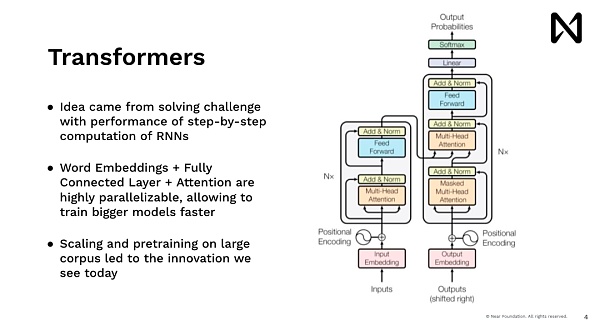
这使我们能够开始进行先进的深度学习,并训练模型来做很多有趣的事情。现在回顾起来,我们当时正在做的是神经元神经网络,它们在很大程度上是模仿人类的模型,我们一次可以读取一个单词。因此,这样做速度非常慢,对吧。如果你试图在Google.com上为用户展示一些内容,没有人会等待去阅读维基百科,比如说五分钟后才给出答案,但你希望马上得到答案。因此,Transformers 模型,也就是驱动ChatGPT、Midjourney以及所有最近的进展的模型,都是同样来自这样的想法,都希望有一个能够并行处理数据、能够推理、能够立即给出答案。
因此这个想法在这里的一个主要创新是,即每个单词、每个token、每个图像块都是并行处理的,利用了我们具有高度并行计算能力的GPU和其他加速器。通过这样做,我们能够以规模化的方式对其进行推理。这种规模化能够扩大训练规模,从而处理自动训练数据。因此,在此之后,我们看到了 Dopamine,它在短时间内做出了惊人的工作,实现了爆炸式的训练。它拥有大量的文本,开始在推理和理解世界语言方面取得了惊人的成果。
现在的方向是加速创新人工智能,之前它是一种数据科学家、机器学习工程师会使用的一种工具,然后以某种方式,解释在他们的产品中或者能够去与决策者讨论数据的内容。现在我们有了这种 AI 直接与人交流的模式。你甚至可能都不知道你在与模型交流,因为它实际上隐藏在产品背后。因此,我们经历了这种转变,从之前那些理解AI 如何工作的,转变成了理解并能够将其使用。

因此,我在这里给你们一些背景,当我们说我们在使用GPU来训练模型时,这不是我们桌面上玩视频游戏时用的那种游戏GPU。

每台机器通常配备八个GPU,它们都通过一个主板相互连接,然后堆叠成机架,每个机架大约有16台机器。现在,所有这些机架也都通过专用的网络电缆相互连接,以确保信息可以在GPU之间直接极速传输。因此,信息不适合CPU。实际上,你根本不会在CPU上处理它。所有的计算都发生在GPU上。所以这是一个超级计算机设置。再次强调,这不是传统的“嘿,这是一个GPU的事情”。所以规模如GPU4的模型在大约三个月的时间里使用了10,000个H100进行训练,费用达到6400万美元。大家了解当前成本的规模是什么样的以及对于训练一些现代模型的支出是多少。
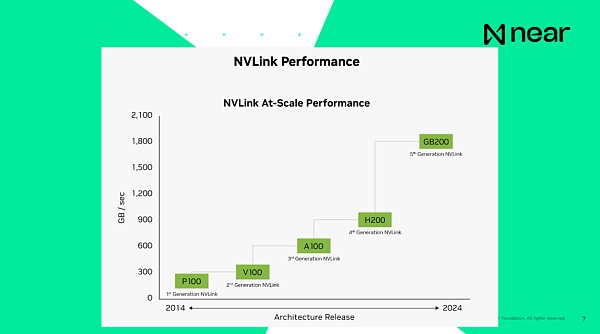
重要的是,当我说系统是相互连接的时候,目前H100的连接速度,即上一代产品,是每秒900GB,计算机内部 CPU 与 RAM 之间的连接速度是每秒 200GB,都是电脑本地的。因此,在同一个数据中心内从一个GPU发送数据到另一个GPU的速度比你的计算机还快。你的计算机基本上可以在箱子里自己进行通信。而新一代产品的连接速度基本上是每秒1.8TB。从开发者的角度来看,这不是一个个体的计算单元。这些是超级计算机,拥有一个巨大的内存和计算能力,为你提供了极大规模��计算。

现在,这导致了我们面临的问题,即这些大公司拥有资源和能力来构建这些模型,这些模型现在几乎已经为我们提供了这种服务,我不知道其中究竟有多少工作,对吧?所以这就是一个例子,对吧?你去找一个完全集中式的公司提供者,然后输入一个查询。结果是,有几个团队并不是软件工程团队,而是决定结果如何显示的团队,对吧?你有一个团队决定哪些数据进入数据集。
举个例子,如果你只是从互联网上爬取数据,关于巴拉克·奥巴马出生在肯尼亚和巴拉克·奥巴马出生在夏威夷的次数是完全相同的,因为人们喜欢猜测争议。所以你要决定要在什么上进行训练。你要决定过滤掉一些信息,因为你不相信这是真的。因此,若像这样的个人已经决定哪些数据会被采用且存在这些数据,这些决定在很大程度上是由做出它们的人所影响的。你有一个法律团队决定我们不能查看哪些内容是受版权保护,哪些是非法的。我们有一个“道德团队”决定什么是不道德的,我们不应该展示什么内容。
所以在某种程度上,有很多这样的过滤和操纵行为。这些模型是统计模型。它们会从数据中挑选出来。如果数据中没有某些内容,它们就不会知道答案。如果数据中有某些内容,它们很可能会将其视为事实。现在,当你从AI得到一个回答时,这可能会令人担忧。对吧。现在,你理应是从模型那里得到回答,但是没有任何的保证。你不知道结果是如何生成的。一个公司可能会把你的特定会话卖给出价最高的人来实际改变结果。想象一下,你去询问应该买哪种车,丰田公司决定觉得应该偏向丰田这个结果,丰...
Let's discuss why AI needs to be open. My background is in Machine Learning, and I have been working on various machine learning projects for about ten years in my career. Before getting into Crypto, natural language understanding, and founding NEAR, I worked at Google. We have now developed the framework that drives most modern AI, called Transformer. After leaving Google, I started a Machine Learning company so that we could teach machines programming to change how we interact with computers. However, we didn't do this in 2017 or 2018 as it was too early, and there was not enough computational power and data at that time.
We used to attract people from around the world, mostly students, to annotate data for us. They were in China, Asia, and Eastern Europe. Many of these people didn't have bank accounts in these countries. The US was not eager to wire money easily, so we started to think about using blockchain as a solution to our problem. We wanted to pay people globally in a programmatic way, making it easier regardless of where they are. The current challenge of Crypto is that although NEAR has solved many problems, in most cases, you need to buy some Crypto first to transact on the blockchain to earn, which goes against the grain.
Like businesses that say, "Hey, first, you need to buy some company shares in order to use it," this is one of the many problems NEAR is solving. Now let's delve a little deeper into the field of artificial intelligence. Language models are not something new; they have been around since the 1950s. They are a statistical tool widely used in natural language processing. For a long time, since 2013, when deep learning was revitalized, a new innovation began. This innovation allows you to match words, add them to multi-dimensional vectors, and convert them into mathematical forms. This works well with deep learning models, which are essentially just a lot of matrix multiplications and activation functions.
This enables us to engage in advanced deep learning, training models to do many interesting things. Looking back now, what we were doing then was neural networks that, to a large extent, mimic the human model, processing one word at a time. So, it was very slow, right? If you try to show content to users on Google.com, nobody will wait to read Wikipedia, for example, five minutes later for an answer, but you want to get the answer immediately. Therefore, models like Transformers, which drive ChatGPT, Midjourney, and all the recent advancements, all stem from this idea of wanting something that can process data in parallel, reason, and provide answers instantly.
So, the main innovation here is that every word, every token, every image block is processed in parallel, leveraging our highly parallel computing power of GPUs and other accelerators. By doing this, we can infer at scale. This scalability allows for the scaling up of training to handle large volumes of training data. Therefore, after this, we saw Dopamine, which did amazing work in a short amount of time, achieving explosive training. It had a lot of text, starting to achieve remarkable results in reasoning and understanding world languages.
Now the direction is to accelerate the innovation of artificial intelligence. Previously, it was a tool used by data scientists and machine learning engineers, and then somehow, explained in their products or could go to discussions with decision-makers about the content of the data. Now we have this mode where AI directly communicates with people. You may not even know you are conversing with a model because it is actually hidden behind the product. So we have gone through this shift from understanding how AI works to understanding and being able to use it.
When I say we are training models using GPUs, it's not the kind of gaming GPUs we use on our desktops.
Each machine usually comes with eight GPUs, connected to each other via a motherboard and stacked into racks, with each rack having about 16 machines. Now, all these racks are also connected to each other via dedicated network cables to ensure that information can be transmitted at lightning speed directly between GPUs. Therefore, the information is not suited for the CPU. In fact, you won't process it on the CPU at all. All the calculations happen on the GPUs. So this is a supercomputer setup. Again, emphasizing that this is not the traditional "hey, this is a GPU thing." So a model like GPU4 was trained using 10,000 H100s for about three months, costing $64 million. Do you understand the scale of the current costs and the expenditures for training some modern models?
When I mention that the systems are interconnected, the current connection speed for H100, the previous-generation product, is 900GB per second, while the connection speed between the CPU and RAM internally in computers is 200GB per second. So sending data from one GPU to another in the same data center is faster than in your computer. Your computer is essentially able to communicate within the box. And the connection speed for the next-generation product is basically 1.8TB per second. From the developer's perspective, these are not individual computation units. These are supercomputers, with huge memory and computing capabilities providing you with massive-scale computing.
Now, this leads to the problem we are facing, that these large companies have the resources and capabilities to build these models, which almost already provide this service for us. I don't know how much of the work is actually behind the scenes, right? So this is an example, right? You go to a completely centralized company provider and enter a query. The thing is, there are several teams, not software engineering teams, but teams that decide how the results are displayed, right? You have a team deciding which data goes into the dataset.
For example, if you are just scraping data from the internet, the number of times Barack Obama was born in Kenya and Barack Obama was born in Hawaii is exactly the same because people like to speculate controversies. So, you have to decide what to train on. You have to decide to filter out some information because you don't believe it's true. The
Let's discuss why artificial intelligence needs to be opened up. My background is that I have been engaged in various machine learning jobs for about ten years in my career, but before I set foot in natural language understanding and creation, I worked in Google. Now we have developed a framework to drive most modern artificial intelligence. After leaving Google, I started a company so that we can teach machine programming to change how we interact with computers, but we didn't do so in or. At that time, it was too early, and there was no computing power and data to do this. What we did at that time was to attract people from all over the world to do the work of marking data for us. Most of them were students. Many of them were in China, Asia and Eastern Europe, and many of them did not have bank accounts in these countries. The United States was reluctant to send money easily, so we began to want to use blockchain as a solution to our problem. We hoped to pay people all over the world in a programmatic way, so that no matter where they were. It becomes easier. By the way, the current challenge is that although many problems have been solved, usually you need to buy some before you can trade in the blockchain to earn this process. Just like enterprises, they will say, hey, first of all, you need to buy some company shares before you can use it. This is one of the many problems we are solving. Now let's discuss the language model in artificial intelligence a little bit in depth. It is not new. A statistical tool widely used in natural language tools has been restarted with deep learning for a long time since, and a new innovation has begun. This innovation is that you can add words to multi-dimensional vectors and convert them into mathematical forms, which works well with deep learning models. They are just a lot of matrix multiplication and activation functions, which enables us to start advanced deep learning and train models to do many interesting things. Looking back now, I am. What scientists were doing at that time was neural networks, which largely imitated the human model. We could read one word at a time, so it was very slow, right? If you tried to show users something on the Internet, no one would wait to read Wikipedia, for example, for five minutes before giving an answer, but you wanted to get the answer right away, so the model was the driver and all the recent models all came from the same idea. According to reasoning, the answer can be given immediately, so one of the main innovations of this idea here is that every word and every image block are processed in parallel, using our highly parallel computing ability and other accelerators. By doing so, we can reason it in a large-scale way, which can expand the training scale and process the automatic training data, so after that, we saw that it has done amazing work in a short time and realized explosive training. With a large number of texts, we have made amazing achievements in reasoning and understanding the world language. Now the direction is to accelerate the innovation of artificial intelligence, which is a tool that data scientists and machine learning engineers will use, and then explain it in their products in some way or discuss the content of data with decision makers. Now we have this mode of direct communication with people, and you may not even know that you are communicating with the model because it is actually hidden behind the product, so we. After this change, from those who understood how to work before to those who can understand and use it, so I'm here to give you some background. When we say that we are using it to train the model, this is not the kind of game we use when playing video games on our desktop. Each machine is usually equipped with eight, and they are all connected to each other through a motherboard and then stacked into racks. There are about one machine in each rack. Now all these racks are also connected to each other through special network cables to ensure that information can be stored in. The information is not suitable for direct speed transmission, so in fact, you can't handle it at all, all the calculations take place on the internet, so this is a supercomputer setup. Again, this is not traditional. Hey, this is a new thing, so the model with a scale of about three months has used one for training, and the training cost has reached 10,000 US dollars. It is important for everyone to understand what the current cost is and how much it costs to train some modern models. At that time, the current connection speed, that is, the connection speed between computers in the previous generation products is local to computers every second, so the speed of sending data from one to another in the same data center is faster than that of your computer. Your computer can basically communicate by itself in the box, while the connection speed of the new generation products is basically every second. From the developer's point of view, this is not an individual computing unit. These are supercomputers with a huge memory and meter. Computing power has provided you with extremely large-scale computing, which now leads to the problem that these large companies have the resources and ability to build these models, and these models have almost provided us with this service. I don't know how much work there is, right? So this is an example, right? You go to a completely centralized company provider and enter a query. The result is that there are several teams, not software engineering teams, but teams that decide how to display the results, right? For example, if you just crawl data from the Internet, the number of times Barack Obama was born in Kenya and Barack Obama was born in Hawaii is exactly the same. Because people like to guess the controversy, you have to decide what to train on. You have to decide to filter out some information because you don't believe it is true. Therefore, if an individual like this has decided which data will be used and there are these data, these decisions are in a long way. To some extent, it is influenced by the people who make them. You have a legal team to decide which content is copyrighted and which is illegal. We have a moral team to decide what is immoral and what we should not show. So to some extent, there are many such filtering and manipulation behaviors. These models are statistical models. If there is no certain content in the data, they will not know the answer. If there is some content in the data, they will probably regard it as a fact. Now when you get an answer from it, this may be worrying, right? Now you should be a model. 比特币今日价格行情网_okx交易所app_永续合约_比特币怎么买卖交易_虚拟币交易所平台
注册有任何问题请添加 微信:MVIP619 拉你进入群

打开微信扫一扫
添加客服
进入交流群
1.本站遵循行业规范,任何转载的稿件都会明确标注作者和来源;2.本站的原创文章,请转载时务必注明文章作者和来源,不尊重原创的行为我们将追究责任;3.作者投稿可能会经我们编辑修改或补充。














