
ABCDE:深入探讨 ZK 协处理器及其未来



撰文:Kris & Laobai ABCDE / Mo Dong Celer Network
随着近几个月协处理器概念的火热,这一新的ZK用例开始得到越来越多人的关注。
然而我们发现,大多数人对于协处理器概念还是相对陌生,尤其是对于协处理器的精准定位 — 协处理器是什么,又不是什么,还比较模糊。而对于市面上几家协处理器赛道的技术方案对比,尚未有人系统的整理过,这篇文希望能够给市场和用户一个关于协处理赛道更加清晰的认识。
一.协处理器Co-Processor是什么,又不是什么
如果要求你只用一句话来向一个非技术或是开发人员讲清楚协处理器,你会如何描述?
我想董沫博士的这句可能非常接近标准答案 — 协处理器说白了就是”赋予智能合约Dune Analytics的能力”。
这句话该如何拆解?
想象一下我们使用Dune的场景 — 你想要去Uniswap V3做LP赚点手续费,于是乎你打开Dune,找到最近Uniswap上各种交易对的交易量,手续费近7天的APR,主流交易对的上下波动区间等等…
又或者StepN火了那会,你开始炒鞋,不确定什么时候该脱手,于是你每天盯着Dune上面StepN的数据,每日交易量,新增用户数,鞋子地板价……打算一旦出现增长放缓或是下跌趋势就赶紧跑。
当然,可能不仅你在盯着这些数据,Uniswap和StepN的开发团队也同样关注这些数据。
这些数据非常有意义 — 它不仅可以帮助判断趋势的变化,还可以以此玩出更多的花样,正如互联网大厂常用的“大数据”打法。
比如根据用户经常买卖的鞋子风格与价格,推荐类似的鞋子。
比如根据用户持有创世鞋子的时长,推出一个“用户忠诚奖励计划”,给予忠诚用户更多的空投或是福利。
比如根据Uniswap上面LP或是Trader提供的TVL或是交易量推出一个类似Cex的VIP方案,给予Trader交易手续费减免或是LP手续费份额增加的福利
……
这时问题来了 — 互联网大厂玩大数据+AI,基本是个黑箱,想怎么弄怎么弄,用户看不到,也不在乎。
但在Web3这边,透明,去信任是咱们天然的政治正确,拒绝黑箱!
于是乎当你想要实现上述场景之时,会面临一个两难之境 — 要么你通过中心化的手段去实现,“后台手动”用Dune统计完这些索引数据,然后去部署实施;要么你写一套智能合约,自动去链上抓取这些数据,完成计算,自动部署分。
前者会让你陷入“政治不正确”的信任问题。
后者在链上产生的Gas费用会是个天文数字,你(项目方)的钱包承受不起。
这时候就是协处理器登场的时候了,把刚才那两种手段结合一下,同时把“后台手动”这个步骤通过技术手段“自证清白”,换句话说,通过ZK技术把链外“索引+计算”这一块“自证清白”了,然后喂给智能合约,这样信任问题解决,海量的Gas费用也不见了,完美!
为什么会叫做“协处理器”呢?其实这是来源于Web2.0发展历史中的“GPU”。GPU之所以在当时被引入作为一个单独的计算硬件,独立于CPU存在,是因为他的设计架构能够处理一些CPU从根本上就难以处理的计算,比如大规模的并行重复计算,图形计算等等。正是有了这种“协处理器”的架构,我们今天才有了精彩的CG电影,游戏,AI模型等等,所以这种协处理器的架构实际上是计算计体系架构的一次飞跃。现在各家协处理器团队也是希望将这种架构引入Web3.0,在这里区块链就类似于Web3.0的CPU,不论是L1还是L2,都天生不适应这类“重数据”和“复杂计算逻辑”的任务,所以引入一个区块链协处理器,来帮助处理这类计算,从而极大拓展区块链应用的可能性。
所以协处理器做的事情归纳一下就是两件事:
从区块链上拿数据,并通过ZK证明我拿的数据是真的,没掺假;
根据刚才拿到的数据做出相应的计算,并再次通过ZK证明我算的结果也是真的,没掺假,计算结果就可以被智能合约“低费用+Trustless”的调用了。
前段时间Starkware那边火了一个概念,叫做Storage Proof,也叫State Proof,基本上做的就是步骤1,代表是,Herodotus,Langrage等等,许多基于ZK技术的跨链桥的技术重点也在步骤1上。
协处理器无非也就是步骤1完事儿之后再加一个步骤2,免信任提取数据之后再做个免信任计算就OK了。
所以用一个相对技术一点的话来精确形容,协处理器应该是Storage Proof/State Proof的超集,是Verfiable Computation(可验证计算)的一个子集。
要注意的一点是,协处理器不是Rollup。
从技术上讲,Rollup的ZK证明类似于上述步骤2,而步骤1“拿数据”这个过程,是通过Sequencer直接实现的,即便是去中心化Sequencer,也只是通过某种竞争或是共识机制去拿,而非Storage Proof这种ZK的形式。更重要的是ZK Rollup除了计算层之外,还要实现一个类似L1 区块链的存储层,这个存储是永久存在的,而ZK Coprocessor则是“无状态”的,进行完计算之后,不需要保留所有状态。
从应用场景来讲,协处理器可以看做所有Layer1/Layer2的一个服务型插件,而Rollup则是自己重新起一个执行层,帮助结算层扩容。
二. 为什么非得用ZK,用OP行不行?
看完上面,你可能会有一个疑惑,协处理器,非得用ZK来做么?听起来怎么这么像是一个“加了ZK的Graph”,而我们似乎对于Graph上面的结果也没有什么“大的怀疑”。
说是这么说,那是因为平常你用Graph的时候基本上不怎么牵扯真金白银,这些索引都是服务off-chain services的,你在前端用户界面上看到的,交易量,交易历史等等数据,可以通过graph,Alchemy,Zettablock等多家数据索引提供商来提供,但这些数据没法塞回到智能合约里面,因为一旦你塞回去就是去增加了额外的对这个索引服务的信任。当数据跟真金白银,尤其是那种大体量的TVL进行联动之时,这种额外的信任就变得重要起来,想象下一个朋友问你借100块,你可能眼都不眨说给就给了,问你借1万,甚至100万的时候呢?
但话又说回来,是不是协处理上面所有的场景真的都得用ZK来做呢? 毕竟Rollup里面我们就有OP和ZK两条技术路线,最近流行的ZKML,也有相应分支路线的OPML概念提出,那么协处理器这事儿,是不是也有个OP的分支,比如说OP-Coprocessor?
其实还真的有 — 不过在此我们先对具体的细节保密,很快我们将会发布更细节的信息出来。
三. 协处理器哪家强 — 市面上常见的几家协处理器技术方案对比
Brevis:
Brevis 的架构由三个组件组成:zkFabric、zkQueryNet 和 zkAggregatorRollup。
如下是一个Brevis的架构图:
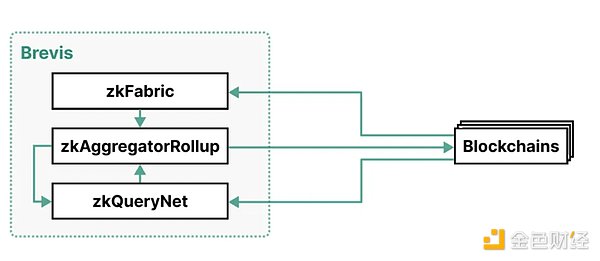
zkFabric: 从所有连接的区块链中收集区块头,并生成证明这些区块头有效性的 ZK 共识证明。通过 zkFabric, Brevis 实现了对多链可互操作的协处理器,也就是能够让一个区块链访问另外一个区块链的任意历史数据。
zkQueryNet: 一个开放的 ZK 查询引擎市场,可接受来自 dApp 的数据查询,并对其进行处理。数据查询使用来自 zkFabric 的经过验证的区块头处理这些查询,并生成 ZK 查询证明。这些引擎既有高度专业化的功能,也有通用化的查询语言,可满足不同的应用需求。
zkAggregatorRollup: 一个 ZK 卷积区块链,充当 zkFabric 和 zkQueryNet 的聚合和存储层。它验证来自这两个组件的证明,存储经过验证的数据,并将其经过 zk 验证的状态根提交到所有连接的区块链上。
ZK Fabric 作为为区块头生成 proof 的关键部分,保证这一部分的安全是非常重要的,如下为 zkFabric 的架构图:
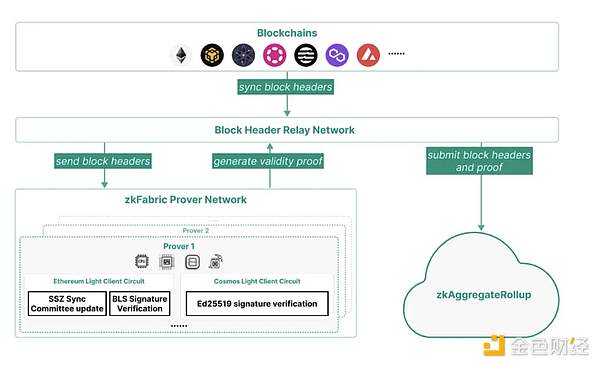
zkFabric基于零知识证明(ZKP)的轻客户端使其完全免于信任,无需依赖任何外部验证实体。无需依赖任何外部验证实体,因为其安全性完全来自于因为其安全性完全来自于底层区块链和数学上可靠的证明。
zkFabric Prover 网络为每个区块链的 lightclient 协议实现电路,该网络为区块头生成有效性证明。证明者可利用 GPU、FPGA 和 ASIC 等加速器,最大限度地减少证明时间和成本。
zkFabric依赖于区块链和底层加密协议的安全假设和底层加密协议的安全假设。不过,要确保 zkFabric 的有效性,至少需要一个诚实的中继器来同步正确的fork。因此,zkFabric采用了去中心化的中继网络而不是单个中继器来优化 zkFabric 的有效性。这种中继网络可以利用现有的结构,如 Celer 网络中的状态监护网络。
证明者分配: 证明者网络是一个分散的 ZKP 证明者网络、需要为每个证明生成任务选择一个证明者,并向这些证明者支付费用。
目前的部署:
目前为各种区块链(包括以太坊 PoS、Cosmos Tendermint 和 BNB Chain)实现的轻客户端协议作为示例和概念验证。
Brevis目前已经跟uniswap hook开展合作,hook大大添加了自定义uniswap 池,但与CEX相比,UnisWap仍然缺乏有效的数据处理功能来创建依赖大型用户交易数据(例如基于交易量的忠诚度计划)的功能。
在Brevis的帮助下,hook解决了挑战。hook现在可以从用户或LP的完整历史链数据中读取,并以完全无信任的方式运行可自定义的计算。
2. Herodotus
Herodotus 是一个强大的数据访问中间件,它为智能合约提供如下跨以太坊层同步访问当前和历史链上数据的功能:
L1 states from L2s
L2 states from both L1s and other L2s
L3/App-Chain states to L2s and L1s
Herodotus提出存储证明这个概念,存储证明融合了包含证明(确认数据的存在)和计算证明(验证多步骤工作流的执行),以证明大型数据集(如整个以太坊区块链或rollup)中一个或多个元素的有效性。
区块链的核心是数据库,其中的数据使用 Merkle 树、Merkle Patricia 树等数据结构进行加密保护。这些数据结构的独特之处在于,一旦数据被安全地提交给它们,就可以产生证据来确认数据包含在结构内。
Merkle 树和 Merkle Patricia 树的使用增强了以太坊区块链的安全性。通过在树的每个级别对数据进行加密散列,几乎不可能在不被发现的情况下更改数据。对数据点的任何更改都需要更改树上相应的哈希值到根哈希值,这在区块链标头中公开可见。区块链的这一基本特征提供了高水平的数据完整性和不变性。
其次,这些树可以通过包含证明进行有效的数据验证。例如,当验证交易的包含或合约的状态时,无需搜索整个以太坊区块链,只需验证相关 Merkle 树内的路径即可。
Herodotus定义的存储证明是以下内容的融合:
包含证明:这些证明确认加密数据结构(例如 Merkle 树或 Merkle Patricia 树)中特定数据的存在,确保相关数据确实存在于数据集中。
计算证明:验证多步骤工作流程的执行,证明广泛数据集中一个或多个元素的有效性,例如整个以太坊区块链或汇总。除了指示数据的存在之外,它们还验证应用于该数据的转换或操作。
零知识证明:简化智能合约需要交互的数据量。零知识证明允许智能合约在不处理所有基础数据的情况下确认索赔的有效性。
Workflow :
1. 获得区块哈希
区块链上的每个数据都属于特定的区块。区块哈希作为该区块的唯一标识符,通过区块头来总结其所有内容。在存储证明的工作流程中,首先需要确定和验证包含我们感兴趣的数据的区块的区块哈希,这是整个过程中的首要步骤。
2. 获得区块头
一旦获得了相关的区块散列,下一步就是访问区块头。为此,需要与上一步获取的区块哈希值相关联的区块头进行哈希处理。然后,将提供的区块头的哈希值与所得的区块哈希值进行比较:
取得哈希的方式有两种:
(1)使用BLOCKHASH opcode 来检索
(2)从 Block Hash Accumulator来查询历史中已经被验证过的区块的哈希
这一步骤可确保正在处理的区块头是真实的。该步骤完成后,智能合约就可以访问区块头中的任何值。
3. 确定所需的根 (可选)
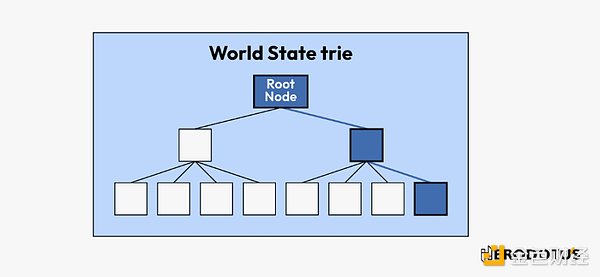
有了区块头,我们就可以深入研究它的内容,特别是:
stateRoot: 区块链发生时整个区块链状态的加密摘要。
receiptsRoot: 区块中所有交易结果(收据)的加密摘要。
事务根(transactionsRoot): 区块中发生的所有交易的加密摘要。
跟可以被解码,使得能够核实区块中是否包含特定账户、收据或交易。
4. 根据所选根来验证数据(可选)
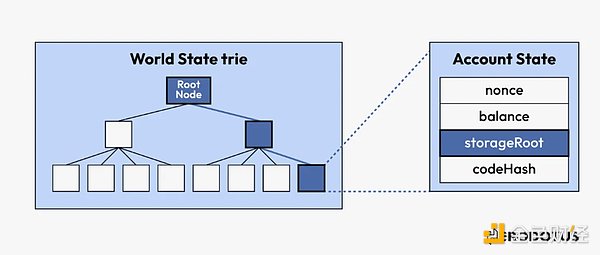
有了我们所选的根,并考虑到以太坊采用的是 Merkle-Patricia Trie 结构,我们就可以利用 Merkle 包含证明来验证树中是否存在数据。验证步骤将根据数据和区块内数据的深度而有所不同。
目前支持的网络:
From Ethereum to Starknet
From Ethereum Goerli* to Starknet Goerli*
From Ethereum Goerli* to zkSync Era Goerli*
3. Axiom
Axiom提供了一种方式可以让开发人员从以太坊的整个历史记录中查询区块头,帐户或存储值。AXIOM引入了一种基于密码学的链接的新方法。Axiom返回的所有结果均通过零知识证明在链上验证,这意味着智能合约可以在没有其他信任假设的情况下使用它们。
Axiom最近发布了Halo2-repl ,是一个基于浏览器的用 Javascript 编写的 halo2 REPL。这使得开发人员只需使用标准的 Javascript 就能编写 ZK 电路,而无需学习 Rust 等新语言、安装证明库或处理依赖关系。
Axiom 由两个主要技术组件组成:
AxiomV1 — 以太坊区块链缓存,从 Genesis 开始。
AxiomV1Query — 执行针对 AxiomV1 查询的智能合约。
(1)在 AxiomV1 中缓存区块哈希值:
AxiomV1智能合约以两种形式缓存自创世区块以来的以太坊区块哈希:
首先, 缓存了连续1024个区块哈希的Keccak Merkle根。这些Merkle根通过ZK证明进行更新,验证区块头哈希是否形成以EVM直接可访问的最近256个区块之一或已存在于AxiomV1缓存中的区块哈希为结束的承诺链。
其次。Axiom从创世区块开始存储这些Merkle根的Merkle Mountain Range。该Merkle Mountain Range是在链上构建的,通过对缓存的第一部分Keccak Merkle根进行更新。
(2)在AxiomV1Query中履行查询:
AxiomV1Query智能合约用于批量查询,以实现对历史以太坊区块头、账户和账户存储的任意数据的无信任访问。查询可以在链上进行,并且通过针对AxiomV1缓存的区块哈希进行的ZK证明来在链上完成。
这些ZK证明检查相关的链上数据是否直接位于区块头中,或者位于区块的账户或存储Trie中,通过验证Merkle-Patricia Trie的包含(或不包含)证明来实现。
4. Nexus
Nexus 试图利用零知识证明为可验证的云计算搭建一个通用平台。目前是machine archetechture agnostic 的,对risc 5/ WebAssembly/ EVM 都支持。Nexus利用的是supernova的证明系统,团队测试生成证明所需的内存为6GB,未来还会在此基础上优化使得普通的用户端设备电脑可以生成证明。
确切的说,架构分为两部分:
Nexus zero:由零知识证明和通用 zkVM 支持的去中心化可验证云计算网络。
Nexus: 由多方计算、状态机复制和通用 WASM 虚拟机驱动的分散式可验证云计算网络。
Nexus 和 Nexus Zero 应用程序可以用传统编程语言编写,目前支持 Rust,以后将会支持更多的语言。
Nexus 应用程序在去中心化云计算网络中运行,该网络本质上是一种直接连接到以太坊的通用 “无服务器区块链”。因此,Nexus 应用程序并不继承以太坊的安全性,但作为交换,由于其网络规模缩小,可以获得更高的计算能力(如计算、存储和事件驱动 I/O)。Nexus 应用程序在专用云上运行,该云可达成内部共识,并通过以太坊内部可验证的全网阈值签名提供可验证计算的 “证明”(而非真正的证明)。
Nexus Zero 应用程序确实继承了以太坊的安全性,因为它们是带有零知识证明的通用程序,可以在 BN-254 椭圆曲线上进行链上验证。
由于 Nexus 可在复制环境中运行任何确定性 WASM 二进制文件,预计它将被用作证明生成应用的有效性/分散性/容错性来源,包括 zk-rollup排序器、乐观的 rollup 排序器和其他证明器,如 Nexus Zero 的 zkVM 本身。
With the hot concept of coprocessor in recent months, this new use case has begun to attract more and more attention. However, we find that most people are still relatively unfamiliar with the concept of coprocessor, especially the precise positioning of coprocessor. What is a coprocessor and what is not? However, the comparison of technical schemes of several coprocessor tracks on the market has not been systematically sorted out. This article hopes to give the market and users a clearer understanding of coprocessor tracks. What is a coprocessor and what isn't it? If you are asked to explain it clearly to a non-technical or developer in one sentence, how would you describe it? I think Dr. Dong Mo's sentence may be very close to the standard answer. To put it bluntly, how should a coprocessor be disassembled? Imagine the scene we use. You want to earn some fees, so you open the fluctuation zone of the mainstream transaction pairs in recent days. At that time, you started to speculate on shoes, and you were not sure when to sell them, so you stared at the above data every day, the daily transaction volume increased, the number of users increased, and the price of shoes and floors planned to run as soon as there was a slowdown or a downward trend. Of course, you may not only stare at these data, but also pay attention to these data, which is very meaningful. It can not only help to judge the changes of trends, but also play more tricks, just like the big data commonly used by Internet manufacturers. For example, recommend shoes with similar styles and prices according to the shoes that users often buy and sell, for example, launch a user loyalty reward plan according to the length of time that users hold Chuangshi shoes, and give loyal users more airdrops or benefits, for example, launch a similar plan according to the above or the provided or transaction volume, and give the benefits of transaction fee reduction or fee share increase. At this time, the problem comes that Internet giants play big data, which is basically a black box, and users can't see it or care. It is our natural political correctness to trust transparently here and reject the black box, so when you want to realize the above scenario, you will face a dilemma. Either you will use centralized means to realize the background manual statistics of these index data and then deploy and implement it, or you will write a set of intelligent contracts to automatically grab these data on the chain, complete the calculation and automatically deploy the points. The former will make you fall into politically incorrect trust problems, and the latter will generate an astronomical amount of money on the chain. The package can't afford it. At this time, it's time for the coprocessor to come on stage. Combine the two methods just now, and at the same time, the manual step in the background is self-certified by technical means. In other words, the off-chain index calculation is self-certified by technology, and then it is fed to the smart contract to solve the massive trust problem. Why is it called the coprocessor? In fact, it came from the development history and was introduced as a separate computing hardware independent of storage at that time. Now, because his design architecture can handle some calculations that are fundamentally difficult to handle, such as large-scale parallel repeated calculation, graphic calculation and so on, it is precisely because of this coprocessor architecture that we have a wonderful movie Game model and so on today, so this coprocessor architecture is actually a leap forward in the computer architecture, and now various coprocessor teams also hope to introduce this architecture here. The blockchain is similar, and it is inherently unsuitable for this kind of multiplicity. According to the task of complex computing logic, a blockchain coprocessor is introduced to help deal with this kind of calculation, thus greatly expanding the possibility of blockchain application. Therefore, what the coprocessor does is to sum up two things: take data from the blockchain and make corresponding calculations according to the data I just got by proving that the results I calculated are also true without adulteration, and the calculation results can be called by the smart contract at a low cost some time ago. The concept of "basically doing" is called "step representing yes" and so on. The technical emphasis of many technology-based cross-chain bridges is also on the step, that is, after the step is completed, add a step to extract data without trust, and then do a trust-free calculation. Therefore, it is necessary to use a relatively technical word to accurately describe the superset that the coprocessor should be a subset of verifiable calculation. It should be noted that the coprocessor is not technically proved to be similar to the above steps. The process of taking data suddenly and step by step is realized directly, even if it is decentralized, it is only taken through some kind of competition or consensus mechanism, rather than this form. More importantly, in addition to the computing layer, a storage layer similar to blockchain should be realized, which is permanent and stateless. After the calculation, it is not necessary to keep all the States. From the application scenario, the coprocessor can be regarded as all a service plug-in and re-establish an execution layer help knot by itself. Calculation layer expansion II Why do you have to use it? After reading the above, you may have a doubt. Does the coprocessor have to be used? It sounds so like an addition, and we don't seem to have any big doubts about the above results. That's because when you use it, you basically don't involve real money. These indexes are all services. The transaction volume, transaction history and other data you see on the front-end user interface can be provided by many data index providers, but These data can't be stuffed back into the smart contract, because once you plug it back, it will increase the extra trust in this indexing service. When the data is linked with real money, especially the general amount, this extra trust becomes important. Imagine that the next friend asks you to borrow a block, and you may give it without blinking an eye, but then again, is it necessary to co-handle all the above scenarios? After all, we have two in it. The technical route is popular recently, and the concept of corresponding branch route is put forward. So is there a new branch of coprocessor? For example, there really is. But here we will keep the specific details secret first, and soon we will release more detailed information. Which coprocessor is stronger than several common coprocessor technical solutions on the market? The architecture is composed of three components and the following is a new architecture diagram. Collecting block headers from all connected blockchains and generating a consensus to prove the effectiveness of these block headers proves that a multi-chain interoperable coprocessor can be realized, that is, a blockchain can be enabled. 比特币今日价格行情网_okx交易所app_永续合约_比特币怎么买卖交易_虚拟币交易所平台
注册有任何问题请添加 微信:MVIP619 拉你进入群

打开微信扫一扫
添加客服
进入交流群
1.本站遵循行业规范,任何转载的稿件都会明确标注作者和来源;2.本站的原创文章,请转载时务必注明文章作者和来源,不尊重原创的行为我们将追究责任;3.作者投稿可能会经我们编辑修改或补充。














