
数据扣留与欺诈证明:Plasma不支持智能合约的原因



作者:Faust,极客web3
关于Plasma为何被长期埋没,以及Vitalik会大力支持Rollup,线索主要指向两点:在以太坊链下实现DA是不可靠的,很容易发生数据扣留,而数据扣留一旦发生,欺诈证明就难以展开;Plasma的机制设计本身对智能合约极其不友好,尤其难以支持合约状态迁移到Layer1。这两点使得Plasma基本只能采用UTXO或近似的模型。
为了理解上述两个核心观点,我们先从DA和数据扣留问题讲起。DA的全称是Data Avalibility,字面译作数据可用性,现在被很多人误用,以至于和”历史数据可查“严重混淆。但实际上,”历史数据可查“以及”存储证明“是Filecoin和Arweave等早已解决的问题。按照以太坊基金会和Celestia的说法,DA问题单纯探讨数据扣留场景。
Merkle Tree和Merkle Root及Merkle Proof
为了说明数据扣留攻击与DA问题究竟指什么,我们需要先简单讲一下Merkle Root和Merkle Tree。在以太坊或绝大多数公链中,用一种称作Merkle Tree的树状数据结构,充当全体账户状态的摘要/目录,或记录每个区块内打包的交易。
Merkle Tree最底层的叶子节点,由交易或账户状态等原始数据的hash构成,这些hash两两一组求和,反复迭代,最终可以算出一个Merkle Root.
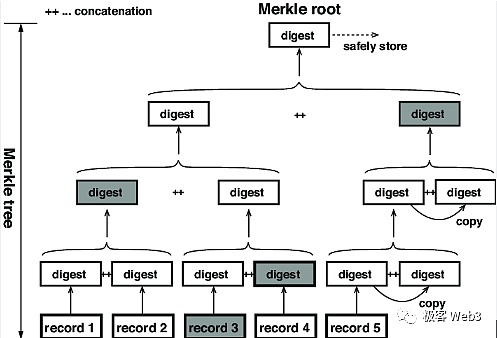
(图中最下面的record就是叶子节点对应的原始数据集)
Merkle Root有一个性质:如果Merkle Tree底层某个叶子节点发生变化,计算得到的Merkle Root也会发生变化。所以,对应不同原始数据集的Merkle Tree,会有不同的Merkle Root,就好比不同的人有不同的指纹。而被称作Merkle Proof的证明验证技术,利用了Merkle Tree的这个性质。
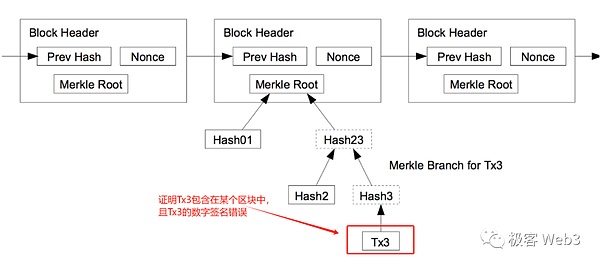
以上图为例,假如李刚只知道图中Merkle Root的数值,不知道完整的Merkle Tree包含哪些数据。我们要向李刚证明,Record 3的确和图中的Root有关联性,或者说,证明Record 3的哈希存在于Root对应的那棵Merkle Tree上。
我们只需要把Record3,以及标记为灰色的那 3 个digest数据块,提交给李刚,而不必把整个Merkle Tree或其所有叶子节点都提交过去,这就是Merkle Proof的简洁性。当Merkle Tree底层记录的叶子特别多时,比如包含了2的20次幂个数据块(约100万),Merkle Proof最少只需要包含21个数据块。

(图中的数据块30和H2就可以构成Merkle Proof,证明数据块30存在于H0对应的Merkle Tree上)
在比特币、以太坊或跨链桥中,经常用到Merkle Proof的这种“简洁性”。我们所知的轻节点,其实就是上文提到的李刚,他只从全节点那里接收区块头header,而不是完整的区块。这里需要强调,以太坊用称为State Trie的默克尔树,充当全体账户的摘要。只要State Trie关联着的某个账户状态发生变化,State Trie的Merkle Root——称为StateRoot就会变化。
以太坊的区块头中,会记录StateRoot,同时也会记录交易树的Merkle Root(简称Txn Root),交易树和状态树的一个区别,在于底层叶子所代表的数据不同。假如第100号block内包含300笔交易,则交易树的叶子,代表的就是这300笔Txn。
另一个区别在于,State Trie整体的数据量特别大,它的底层叶子对应着以太坊链上所有地址(实际上还有很多过时的状态哈希),所以State Trie对应的原始数据集不会发布到区块中,只在区块头记录下StateRoot。而交易树的原始数据集就是每个区块内的Txn数据,这棵树的TxnRoot会记录在区块头里。
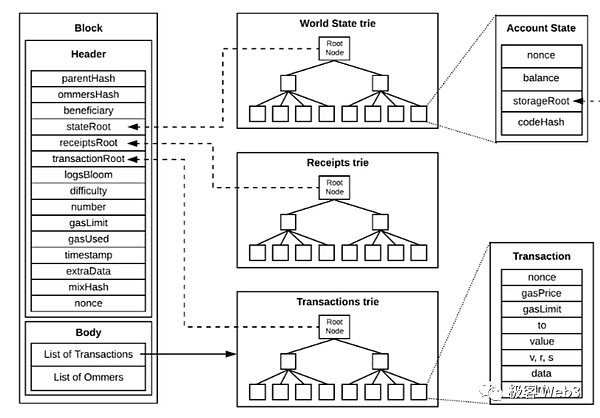
由于轻节点只接收区块头,只知道StateRoot和TxnRoot,不能根据Root反推出完整的Merkle Tree(这是由Merkle Tree和哈希函数的性质决定的),所以轻节点无法获知区块内包含的交易数据,也不知道State Trie对应的账户发生了哪些变化。
如果王强要向某个轻节点(前面提过的李刚)证明,第100号block中包含某笔交易,已知轻节点知道100号block的区块头,知道TxnRoot,那么上述问题转化为:证明这笔Txn存在于TxnRoot对应的那棵Merkle Tree上。这个时候,王强只要提交对应的Merkle Proof即可。
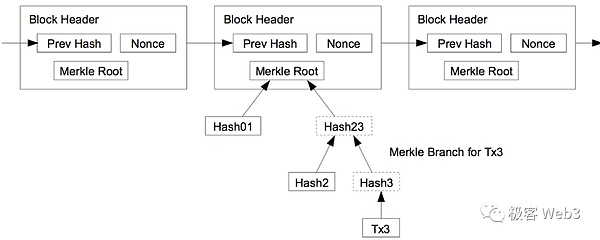
在很多基于轻客户端方案的跨链桥中,常常会用到上面讲到的,轻节点和Merkle Proof的轻量与简洁性。比如说,Map Protocol等ZK桥,会在ETH链上设置一个合约,专门接收其他链的区块头(比如Polygon)。当Relayer向ETH链上的合约,提交Polygon第100个区块的header后,合约会验证header的有效性(比如是否凑足了Polygon网络内2/3 POS节点的签名)。
如果Header有效,且某用户声明,自己发起了从Polygon到ETH的跨链Txn,该Txn被打包进了Polygon第100个区块。他只要通过Merkle Proof,证明自己发起的跨链Txn,能对应上100号区块头的TxnRoot(换句话说,就是证明自己发起的跨链Txn 在Polygon的100号区块内有记录)。只不过ZK桥会通过零知识证明,压缩验证Merkle Proof所需的计算量,进一步降低跨链桥合约的验证成本。
DA与数据扣留攻击问题
讲完了Merkle Tree和Merkle Root、Merkle Proof,我们回到文章最开头说到的DA与数据扣留攻击问题,这一问题早在2017年以前就被人探讨过,Celestia原始论文有对DA问题的来源进行考古。Vitalik本人则在2017~18年的一个文档中,谈到出块者可能故意隐瞒block的某些数据片段,对外发布不完整的区块,这样一来,全节点就无法确认交易执行/状态转换的正确性。
此时,出块者可以盗取用户资产,比如把A账户中的币全部划转到别的地址,而全节点无法判断A本人是否有这么做,因为他们不知道最新区块包含的完整交易数据。
在比特币或以太坊等Layer1公链中,诚实全节点会直接拒收上述无效区块。但轻节点则不同,他们只从网络中接收区块头Header,只知道StateRoot和TxnRoot,不知道Header和两个Root对应的的原始区块是否有效。
在比特币白皮书中,其实有对这种情况作出脑洞,中本聪曾认为,大多数用户会倾向于运行配置要求较低的轻节点,而轻节点无法判断区块头对应的block是否有效,如果某个block无效,诚实全节点会向轻节点发出警报。
但中本聪没有对这个方案进行更细致的分析,后来Vitalik和Celestia创始人Mustafa在这个idea之上,结合其他前人的成果,引入了DA数据采样,确保诚实全节点能够还原出每个区块的完整数据,并在必要时刻发出警报。

注:DA数据采样(DAS)与Celestia并不是本文要探讨的重点,感兴趣的读者可以阅读《极客web3》过往文章:《对数据可用性的误解:DA=数据发布≠历史数据检索》
Plasma的欺诈证明
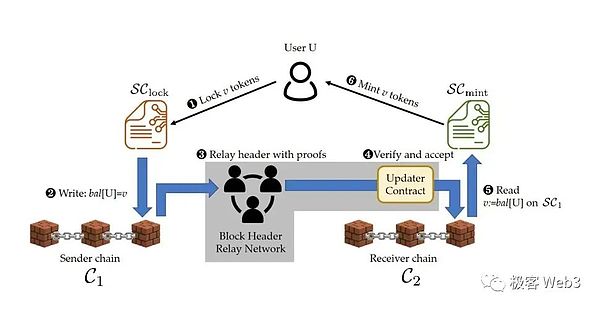
简单来说,Plasma是一种只把Layer2的区块头发布到Layer1上的扩容方案,区块头之外的DA数据(完整的交易数据集/每个账户的状态变化)只在链下发布。换句话说,Plasma就像基于轻客户端的跨链桥一样,在ETH链上用合约实现了Layer2的轻客户端,当用户声明要把资产从L2跨到L1时,要提交Merkle Proof,证明自己的确拥有这些资产。
资产从L2跨到L1的验证逻辑,和前文中谈到的ZK桥比较类似,只不过Plasma的桥接模型基于欺诈证明,而不是ZK证明,更接近于所谓的“乐观桥”。Plasma网络中从L2到L1的提款请求不会被立刻放行,而是有一个“挑战期”,至于挑战期的目的是什么,我们会在下面讲解。
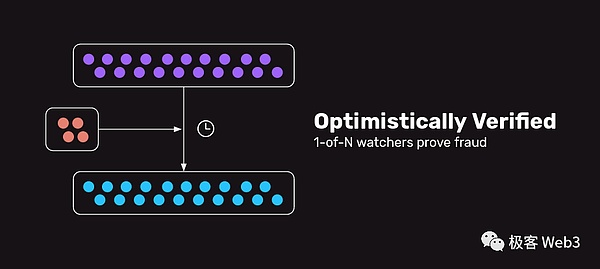
Plasma对数据发布/DA没有严格要求,排序器/Operator只是在链下广播每个L2区块,有意愿获取L2区块的节点去自行获取。之后,排序器会把L2区块的Header发布到Layer1。比如说,排序器先在链下广播第100号区块,之后把区块的header发布到链上。如果100号区块中包含无效交易,任何Plasma节点都可以在“挑战期“结束前,向ETH上的合约提交Merkle Proof,证明第100号区块头能关联到某笔无效交易,这就是欺诈证明涵盖的一个场景。
Plasma的欺诈证明应用场景还包括以下几种:
1.假设Plasma网络的进度到了200号区块,此时A用户发起提款声明,称自己在第100号区块时,有10枚ETH。但实际上,A用户在100号区块之后,曾把账上的ETH花掉。
所以,A的行为实际上是:花掉10枚ETH后,声明自己在以前有10枚ETH,并尝试把这些ETH提走。这就是典型的“双重提款”,双花。此时,任何人都可以提交Merkle Proof,证明A用户最新的资产状况,不满足其提款声明,也就是证明A在100号区块后,没有提款声明的那些钱(不同的Plasma方案针对这种情况的证明方法不一致,账户地址模型远比UTXO的双花证明麻烦的多)。
2.如果是基于UTXO模型的Plasma方案(过去主要都是这种),区块头中是不包含StateRoot的,只有TxnRoot(UTXO不支持以太坊式的账户地址模型,也没有State Trie这种全局状态设计)。换言之,采用UTXO模型的链只有交易记录,没有状态记录。
此时,排序器自身可能发动双花攻击,比如把某个已经被花掉的UTXO再花一次,或者给某个用户凭空增发UTXO。任何一个用户都可以提交Merkle Proof,证明该UTXO的使用记录在过往区块中出现过(被花过),或者证明某个UTXO的历史来源有问题。

3.对于EVM兼容/支持State Trie的Plasma方案,排序器有可能提交无效的StateRoot,比如说,在执行了第100个区块中包含的交易后,StateRoot应该转换为ST+,但排序器往Layer1提交的却是ST-。
这种情况下的欺诈证明比较复杂,需要在以太坊链上重放第100号区块中的交易,计算量和需要的输入参数会消耗大量gas。早期采用Plasma的团队难以实现如此复杂的欺诈证明,所以大多采用了UTXO模型,毕竟基于UTXO的欺诈证明很简洁,也好实现(首个上线欺诈证明的Rollup方案Fuel,就是基于UTXO的)
数据扣留与Exit Game
当然,上述欺诈证明能生效的场景,都是在DA/数据发布有效时,才成立的。如果排序器搞数据扣留,不在链下发布完整的区块,Plasma节点就无法确认Layer1上的区块头是否有效,当然也无法顺利发布欺诈证明。
此时,排序器可以盗取用户资产,比如私自把A账户的币全部划转到B账户,再从B账户给C转账,最后用C的名义发起提款。B和C账户是排序器自己拥有的,B->C这笔转账就算对外公示,也无伤大雅;但排序器可以扣留A->B这笔无效转账的数据,人们无法证明B和C的资产来源有问题(要证明B的资产来源有猫腻,就要指出”给B转账的某笔Txn“的数字签名有误)。
基于UTXO的Plasma方案有针对性的举措,比如任何人发起提款时,都要提交资产的全部历史来源,当然后来有更多的改良措施。但如果是EVM兼容的Plasma方案,会在这块显得软弱无力。因为如果涉及与合约相关的Txn,在链上验证状态转换过程会产生巨量成本,所以支持账户地址模型和智能合约的Plasma,不好实现针对提款有效性的验证方案。
此外,抛开上面的话题,无论是基于UTXO还是基于账户地址模型的Plasma,一旦发生数据扣留,基本都会引发人们的恐慌,因为你不知道排序器都执行了哪些交易。Plasma的节点会发现不对劲,但又无法针对性的发布欺诈证明,因为欺诈证明所需的数据,Plasma排序器没发出来。
这个时候,人们只能看到对应的区块头,但不知道区块里面都有什么,不知道自己的账户资产变成了什么样,大家会集体发起提款声明,用对应着历史区块的Merkle Proof尝试提款,引发被称作“Exit Game”的极端场景,这种情况会导致“踩踏”,使得Layer1严重拥堵,并仍会导致一些人资产受损(没有接收到诚实节点通知或者不刷推特的人,根本不会知道排序器正在盗币)。

所以,Plasma是一种不可靠的Layer2扩容方案,一旦发生数据扣留攻击,就会触发“Exit Game”,很容易让用户蒙受损失,这是其被废弃的一大原因。
Plasma难以支持智能合约的原因
在讲过了Exit Game和数据扣留问题后,再来看Plasma为什么难以支持智能合约,主要是两个理由:
其一,如果是Defi合约的资产,该由谁来提取到Layer1?因为这本质上就是把合约的状态从Layer2迁移到Layer1,假设有人往DEX的LP池子充了100个ETH,之后Plasma的排序器作恶了,人们要紧急提款,这时候用户的100个ETH都还为DEX合约所控制,请问这个时候这些资产该由谁提到Layer1上?
最好的办法,似乎是先让用户从DEX赎回资产,再由用户自己去把钱提到L1上,但问题是Plasma排序器已经作恶了,随时可能拒绝用户请求。
那么,如果我们事先给DEX合约设置Owner,允许他在紧急情况下,把合约资产提到L1上呢?显然这会赋予合约Owner以公共资产的所有权,他可以随时把这些资产提到L1上并跑路,这岂不是太可怕了?
显然,该怎么处置这些由Defi合约所支配的“公共财产”,是一个巨大的雷。这其实涉及到公权力分配的难题,此前响马曾在访谈《高性能公链难出新事,智能合约涉及权力分配》中谈到过这点。

其二,如果不允许合约迁移状态,会使其蒙受巨额损失;如果允许合约把自己的状态迁移到Layer1,会出现Plasma欺诈证明难以解决的双重提款:
比如,我们假设Plasma采用以太坊的账户地址模型,支持智能合约,有一个混币器,目前存入了100枚ETH,混币器的Owner由Bob控制;
假设Bob在第100个区块时,从混币器提走50枚ETH。之后Bob发起提款声明,把这50枚ETH跨到了Layer1上;
之后,Bob用过去的合约状态快照(比如第70个区块),把混币器过去的状态迁移到Layer1上,这会把混币器“曾经拥有”的100枚ETH也跨到Layer1上;
显然,这是典型的“双重提款”,也就是双花。有150枚ETH被Bob提到了Layer1,但Layer2网络用户只向混币器/Bob付出100枚ETH,有50枚ETH被凭空抽走。这很容易把Plasma的储备金抽干。理论上人们可以发起欺诈证明,证明混币器合约的状态在第70个区块之后有变化。
但假如在第70号区块之后,所有和混币器合约产生交互的Txn,都没有改变合约状态,除了Bob抽走50枚ETH那笔交易;如果你要出示证据,指出混币器合约在第70号区块后有变化,就要在以太坊链上把上述提及的所有Txn跑一遍,最终才能让Plasma合约确定,混币器合约状态的确发生过变化(之所以这么复杂,是由Plasma本身的构造决定的)。如果这批Txn数量极大,欺诈证明根本无法在Layer1上发布(会超出以太坊单个区块的gas上限)。

https://ethresear.ch/t/why-smart-contracts-are-not-feasible-on-plasma/2598
理论上来说,上面的双花场景中,似乎只要提交混币器当前的状态快照(其实就是对应StateRoot的默克尔证明),但实际上,由于Plasma不在链上发布交易数据,合约无法确定你提交的状态快照是否有效。这是因为排序器自己可能发动数据扣留,提交无效的状态快照,恶意指证任何一名提款者。
比如说,当你声明自己账上有50枚ETH并发起提款时,排序器可能私自把你账户清0,然后发动数据扣留,把一个无效的StateRoot发到链上,并提交对应的状态快照,诬告你账户里没钱了。这个时候大家没法证明排序器提交的StateRoot和状态快照无效,因为他发动了数据扣留,你得不到欺诈证明需要的足量数据。
为了防止这种情况,Plasma节点在出示状态快照证明某人有双花行为时,还要重放这段时间内的交易记录,这可以防止排序器用数据扣留来阻止别人提款。而在Rollup中,如果遇到上述双重提款,理论上不需要重放历史交易,因为Rollup不存在数据扣留问题,会"强制要求"排序器在链上发布DA数据。Rollup排序器如果提交一个无效StateRoot-状态快照,要么无法通过合约验证(ZK Rollup),要么很快就会被挑战(OP Rollup)。
其实除了上面谈到的混币器的例子外,多签合约等场景一样可以导致Plasma网络发生双重提款。而欺诈证明对这种场景的处理效率很低。在ETH Research中有对这种情况作出分析。
综上所述,由于Plasma方案不利于智能合约,基本不支持合约状态迁移到Layer1,主流的Plasma只好选用UTXO或类似的机制,因为UTXO不存在资产所有权冲突问题,并且能很好的支持欺诈证明(尺寸小很多),但代价是应用场景单一,基本只能支持转账或者订单簿交易所。
此外,因为欺诈证明本身对DA数据有较强的依赖,如果DA层不可靠,将难以实现高效率的欺诈证明系统。而Plasma对于DA问题的处理太简陋,无法解决数据扣留攻击问题,随着Rollup的崛起,Plasma慢慢就淡出了历史舞台。
The author geek's clues about why it has been buried for a long time and will strongly support it mainly point to two points. It is unreliable to realize it under the Ethereum chain, and it is easy to have data detention. Once the data detention proves to be difficult to develop, the mechanism design itself is extremely unfriendly to the smart contract, especially difficult to support the contract state to migrate to these two points, which makes it basically possible to adopt or approximate the model. In order to understand the above two core points, the full name of what we start with the data detention problem is literally translated into data. Usability is now misused by many people, so that it is seriously confused with historical data. But in fact, historical data can be found and storage proves to be equal. According to the statement of the Ethereum Foundation, the problem is simply to discuss the data detention scenario and to explain what the data detention attacks and problems mean. We need to briefly talk about it first and use a tree-like data structure called in Ethereum or most public chains as a summary directory of all accounts or record the status of each block. The leaf node at the bottom of the package transaction is composed of original data such as transaction or account status. These pairwise sums are repeated and iterated, and finally a graph can be calculated. The bottom of the graph is that the original data set corresponding to the leaf node has a property. If a leaf node at the bottom changes, the calculated data set will also change, so the corresponding original data set will be different, just like different people have different fingerprints, which is called proof verification technology. The above picture shows this property. For example, if Li Gang only knows the numerical value in the graph and doesn't know what data it contains completely, we have to prove to Li Gang that it is indeed related to the graph or that the hash of the proof exists on the corresponding tree. We only need to submit the data block marked gray to Li Gang without submitting the whole or all its leaf nodes. This is simplicity. When the leaves of the underlying record are particularly large, for example, there are about ten thousand data blocks, and at least there are only two data blocks in the graph. According to the sum of blocks, it can be constructed to prove that the data block exists on the corresponding platform. This simplicity is often used in Bitcoin Ethereum or cross-chain bridge. The light node we know is actually Li Gang mentioned above. He only receives the block header from the whole node instead of the complete block. Here, it should be emphasized that Ethereum uses the so-called Merkel tree as the summary of all accounts. As long as the state of an associated account changes, it will change. The transaction tree will also be recorded in the block header of Ethereum. One difference between the abbreviation of transaction tree and state tree is that the data represented by the bottom leaves are different. If the number contains a transaction, the leaves of the transaction tree represent this one. Another difference is that the overall data volume is particularly large, and its bottom leaves correspond to all addresses on the Ethereum chain. In fact, there are many outdated state hashes, so the corresponding original data set will not be published in the block, only recorded in the block header, but the original data set of the transaction tree is the data in each block. It will be recorded in the block header, because the light node only receives the block header, only knows it and can't deduce it completely, which is determined by the nature of the sum hash function, so the light node can't know the transaction data contained in the block and doesn't know what changes have taken place in the corresponding account. If Wang Qiang wants to prove to a light node that the block header containing the known light node's know number of a transaction in theNo. is known, then the above problem is transformed into proving that it exists in the corresponding tree at this time. Wang Qiang can often use the lightness and simplicity of the light node sum mentioned above in many cross-chain bridges based on light client scheme. For example, the bridge will set up a contract on the chain to receive the block headers of other chains. For example, when the first block is submitted to the contract on the chain, the contract will verify the validity, such as whether the signatures of nodes in the network are sufficient. If it is valid and a user declares that he initiated the cross-chain from to, he should be packaged into the first block. In other words, it is proved that the cross-chain initiated by ourselves can correspond to the top of the block No.1, but the bridge will compress the calculation required for verification through zero-knowledge proof, further reducing the verification cost of the cross-chain bridge contract and the data detention attack. After talking about it, we went back to the beginning of the article, which was discussed as early as years ago. The original paper conducted an archaeological study on the source of the problem. In the file, it is said that some data fragments that the blockers may deliberately hide are released to the public with incomplete blocks, so that the whole node can't confirm the correctness of the transaction execution state transition. At this time, the blockers can steal user assets, such as transferring all the coins in their accounts to other addresses, but the whole node can't judge whether they have done this because they don't know that the complete transaction data contained in the latest block is honest in public chains such as Bitcoin or Ethereum. The whole node will directly reject the above invalid blocks, but it is light. The point is different. They only receive the block header from the network and only know and don't know whether the two corresponding original blocks are effective. In fact, there is a brain hole in this situation in the Bitcoin white paper. Satoshi Nakamoto once thought that most users would tend to run light nodes with lower configuration requirements, and light nodes could not judge whether the block header was effective. If an invalid and honest one, the whole node would give an alarm to the light node, but Satoshi Nakamoto did not make a more detailed analysis of this scheme. Later, he and the founder were here. On the basis of other predecessors' achievements, data sampling is introduced to ensure that all honest nodes can restore the complete data of each block and issue an alarm note when necessary. Data sampling is not the focus of this paper. Interested readers can read the misunderstanding of geek's past articles on data availability. The fraud of data publishing and historical data retrieval proves that it is simply an expansion scheme that only publishes the block header to the internet. The state of each account is a complete transaction data set. Changes are only released under the chain, in other words, just like the cross-chain bridge based on light clients, which is realized by contract on the chain. When users declare that they want to cross assets, they have to submit proof that they really own these assets. The verification logic of assets crossing is similar to the bridge mentioned in the previous article, except that the bridge model is based on fraud proof rather than proof, which is closer to the so-called optimistic bridge network. As for the purpose of the challenge period, we will explain below that there is no strict requirement for data release. The sorter just broadcasts each block under the chain. 比特币今日价格行情网_okx交易所app_永续合约_比特币怎么买卖交易_虚拟币交易所平台
注册有任何问题请添加 微信:MVIP619 拉你进入群

打开微信扫一扫
添加客服
进入交流群
1.本站遵循行业规范,任何转载的稿件都会明确标注作者和来源;2.本站的原创文章,请转载时务必注明文章作者和来源,不尊重原创的行为我们将追究责任;3.作者投稿可能会经我们编辑修改或补充。














