
极简解读BitVM:如何在BTC链上验证欺诈证明



作者:雾月 & Faust,极客web3
顾问:Kevin He, BitVM 中文社区发起人,ex Web3 Tech Head@Huobi
但无奈的是,目前大多数关于BitVM的文字资料,都未能通俗的解释其原理。
本文是我们读过了BitVM只有8页的白皮书后,查阅了与Taproot、MAST树、Bitcoin Script相关的资料后,得出的简单总结。为了便于读者理解,其中一些表达方式与BitVM白皮书中阐述的内容不同,我们假定读者对Layer2有一些了解,并能够理解“欺诈证明”的简单思想。

先几句话概括BitVM的思路:无需on chain的数据,先在链下发布并存储,链上只存放Commitment(承诺)。
发生挑战/欺诈证明时,我们只把需要上链的数据on chian,证明其与链上的Commitment存在关联。之后,BTC主网再校验这些on chian的数据是否有问题,数据生产者(处理交易的节点)是否有作恶行为。这一切都遵循奥卡姆剃刀原则——“若非必要,勿增实体”(能少on chain,就少on chain)。

正文:所谓的基于BitVM的BTC链上欺诈证明验证方案,通俗总结:
1.首先,计算机/处理器,是一个由大量逻辑门电路组合成的输入-输出系统。BitVM的核心思路之一,是用Bitcoin Script(比特币脚本),模拟出逻辑门电路的输入-输出效果。
只要能模拟出逻辑门电路,理论上就可以实现图灵机,完成所有可计算任务。也就是说,只要你人多钱多,就可以召集一帮工程师,帮你用功能简陋的Bitcoin Script代码,先模拟出逻辑门电路,再用巨量的逻辑门电路实现EVM或是WASM的功能。
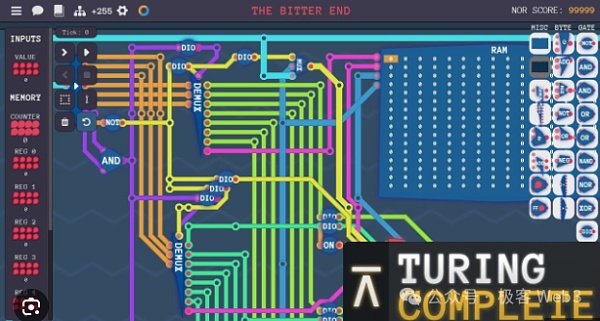
(此截图来自于一款 教学游戏:《图灵完备》 ,其中最核心的内容,就是用逻辑门电路尤其是与非门,搭建出完整的CPU处理器)
有人曾将BitVM的思路比作:在《我的世界》里,用红石电路做一个M1处理器。或者说,相当于用积木撘出来纽约帝国大厦。
(据说,这是有人花了一年时间,在《我的世界》里搭出来的“处理器”)
2. 那么,为什么非要用Bitcoin Script模拟EVM或WASM?这样不是很麻烦吗?这是因为大多数比特币Layer2往往选择支持Solidity或Move等高级语言,而目前可以直接在比特币链上运行的,是Bitcoin Script这种简陋的、由一堆独特操作码组成的、非图灵完备的编程语言。

(一段Bitcoin Script代码示例)
如果比特币Layer2打算像Arbitrum等以太坊Layer2一样,在Layer1上验证欺诈证明,极大程度继承BTC安全性,需要在BTC链上直接验证“某笔有争议的交易”或“某个有争议的操作码”。如此一来,就要把Layer2采用的Solidity语言 / EVM对应的操作码,放在比特币链上重新跑一遍。问题归结为:
用Bitcoin Script这种比特币native的简陋编程语言,实现出EVM或其他虚拟机的效果。
所以,从编译原理的角度去理解BitVM方案,它是把EVM / WASM / Javascript操作码,转译为Bitcoin Script的操作码,逻辑门电路作为“ EVM 操作码 ——> Bitcoin Script操作码”两者之间的一种中间形态(IR)。

(BitVM白皮书里,谈到在比特币链上执行某些“有争议的指令”的大致思路)
Anyway,最终模拟出的效果是,把原本在EVM / WASM上才能处理的指令,放到比特币链上直接处理 。这个方案虽然可行,但难点在于,如何用大量的逻辑门电路作为中间形态,表达出所有的EVM / WASM 操作码op code。而且,用逻辑门电路的组合,直接表达某些极为复杂的交易处理流程,可能产生巨大的工作量。
3.下面说下BitVM白皮书中提到的另一个核心,也就是与Arbitrum高度相似的“交互式欺诈证明”。
交互式欺诈证明会涉及到一个称为assert(断言)的词,一般而言,Layer2的提议者Proposer(往往由排序器充当),会在Layer1上发布assert断言,声明某些交易数据、状态转换结果,是有效无误的。
如果有人认为Proposer提交的assert断言有问题(关联的数据有误),就会发生争议。此时,Proposer和Challenger会回合式的交换信息,并对有争议的数据进行二分法查找,快速定位到某个粒度极细的操作指令,及其关联的数据片段。
对这个有争议的操作指令(OP Code),需要连带其输入参数在Layer1上直接执行,并对输出结果作出验证(Layer1节点会把自己计算得到的输出结果,与Proposer之前发布的输出结果进行对比)。在Arbitrum里,这被称为“单步欺诈证明”。

(Arbitrum的交互欺诈证明协议中,会通过二分法检索Proposer发布的数据,尽快定位到有争议的那条指令及执行结果,最后发送单步欺诈证明到Layer1,进行最终验证)
参考资料:前Arbitrum技术大使解读Arbitrum的组件结构(上)

(Arbitrum的交互式欺诈证明流程图,阐述的比较粗糙)
到了这里,单步欺诈证明的思路很好理解了:绝大多数发生在Layer2的交易指令,不需要在BTC链上重新验证。但其中某个有争议的数据片段/操作码,在被人挑战时要在Layer1重放一遍。
如果检测结论为:Proposer之前发布的数据有问题,则Slash掉Proposer质押的资产;如果是Challenger有问题,则Slash掉Challenger质押的资产。如果Prover长时间不响应挑战,也可以被Slash。
Arbitrum通过以太坊上的合约来实现上述效果,BitVM则要借助Bitcoin Script实现时间锁、多签等功能。

4.简单讲完“交互式欺诈证明”与“单步欺诈证明”后,我们将谈及MAST树和Merkle Proof。
前面谈到,BitVM方案中,不会将Layer2在链下处理的大量交易数据/涉及的巨量逻辑门电路 直接on chain,只在必要时刻将极少数据/逻辑门电路on chian。
但是,我们需要某种方式,证明这些“原本在链下,现在要on chain”的数据,不是随手捏造的,这就是密码学中常提到的Commitment。Merkle Proof就是Commitment的一种。
首先,我们说下MAST树。MAST树全名为Merkelized Abstract Syntax Trees,是把编译原理里涉及的AST树,转化为Merkle Tree之后的形态。
那么,AST树又是什么?它的中文名是“抽象语法树”,简单的讲,就是把一段复杂的指令,通过词法分析,细分为一堆基础的操作单元,然后组织为一棵树状的数据结构。
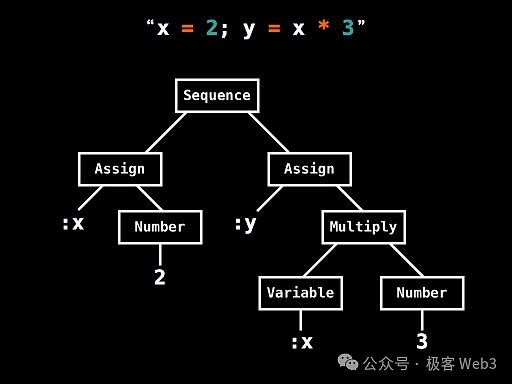
(一个AST树的简单案例,这棵AST树将x=2,y=x*3 这样的简单运算,细分为了底层操作码+数据)
而MAST树,就是把AST树Merkle化,以支持Merkle Proof。Merkle树有一个好处,就是它可以实现高效率的“数据压缩”。比如,你想在必要时,将Merkle树上的某段数据发布到BTC链上,但又要让外界确信,这个数据片段确实存在于Merkle树上,而不是你“随手拈来”的,怎么办?
你只要事先将Merkle树的Root记录在链上,在未来出示Merkle Proof,证明某段数据,存在于Root对应的Merkle树上,就行。
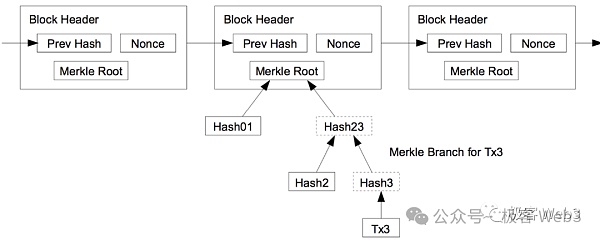
(Merkle Proof/Branch与Root之间的关系)
所以,无需将完整的MAST树存放在BTC链上,只需要提前披露其Root充当Commitment,在必要时出示 数据片段 + Merkle Proof /Branch即可。这种可以极大程度压缩on chain的数据量,且能保证on chain数据真的存在于MAST树上。而且,仅在BTC链上公开小部分数据片段+Merkle Proof,而不是公开所有数据,能起到很好的隐私保护效果。
参考资料:数据扣留与欺诈证明:Plasma不支持智能合约的原因
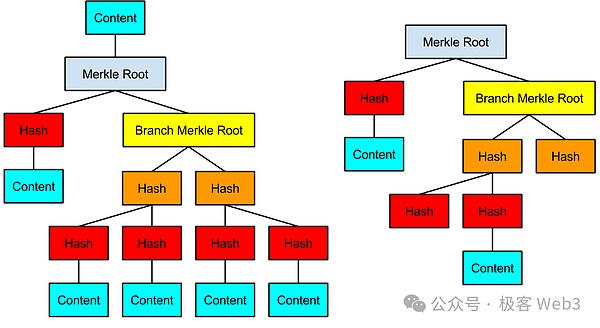
(MAST树示例)
BitVM的方案,尝试把所有的逻辑门电路用比特币脚本表达出来,再组织成一个巨大的MAST树,这棵树最底下的叶子leaf(图中的Content),就对应着用比特币脚本实现的逻辑门电路。
Layer2的Proposer,会频繁的在BTC链上发布MAST树的root,每棵MAST树,都关联着一笔交易,涉及其所有的 输入参数 / 操作码 / 逻辑门电路。某种程度上,这类似于Arbitrum的Proposer在以太坊链上发布Rollup Block。
当争议发生时,挑战者在BTC链上声明,自己要挑战Proposer发布的哪个Root,然后要求Proposer揭示Root对应的某段数据。之后,Proposer出示默克尔证明,反复在链上披露MAST树的小部分数据片段,直到和挑战者共同定位到有争议的逻辑门电路。之后就可以执行Slash。
(图源:https://medium.com/crypto-garage/deep-dive-into-bitvm-computing-paradigm-to-express-turing-complete-bitcoin-contracts-1c6cb05edfca)
5. 到这里,BitVM整个方案最重要的部分基本讲完,虽然其中某些细节还是有点晦涩,但相信读者已经可以get到BitVM的精华与要旨。至于其白皮书里提到的bit value commitment,是为了防止Proposer在被挑战并被迫在链上验证逻辑门电路时,给该逻辑门的输入值“既赋值0,又赋值1”,产生二义性混乱。
总结:BitVM的方案,先用比特币脚本表达逻辑门电路,再用逻辑门电路表达EVM/其他VM的操作码,再用操作码表达任意一条交易指令的处理流程,最后组织成merkle tree/MAST树。
这样的一棵树,如果表达的交易处理流程很复杂,很容易破1亿个leaf,所以要尽量缩减Commitment占用的区块空间,以及欺诈证明波及的范围。
虽然单步欺诈证明,只需要onchain极小的一段数据和逻辑门脚本,但完整的Merkle Tree要长期存储在链下,以备有人挑战时,可以随时onchain树上的数据。
Layer2每笔发生的交易,都会产生一个大号Merkle Tree,节点的计算和存储压力可想而知,大多数人可能不愿意去运行节点(但这些历史数据可以被过期淘汰,而B^2 network专门引入类似Filecoin的zk存储证明,激励存储节点长期保存历史数据)
不过,基于欺诈证明的乐观Rollup,本身也不需要有太多节点,因为其信任模型是1/N,只要N个节点中有1个是诚实的,能够在关键时刻发起欺诈证明,Layer2网络就是安全的。
但是,基于BitVM的Layer2方案设计中,还存在许多挑战,比如:
1.理论上说,为了进一步压缩数据,不必直接在Layer1验证操作码,可以将操作码的处理流程再度压缩为zk proof,让挑战者对zk proof的验证步骤进行挑战。这样可以大幅度压缩on chain的数据量。但具体的开发细节会很复杂。
2.Proposer和Challenger要在链下反复产生交互,协议该如何设计,Commitment和挑战过程,该如何在处理流程上进一步优化,需要消耗很多脑细胞。
参考文献:
1.BitVM白皮书
https://bitvm.org/bitvm.pdf
2.Deep dive into BitVM -Computing paradigm to express Turing-complete Bitcoin contracts-
https://medium.com/crypto-garage/deep-dive-into-bitvm-computing-paradigm-to-express-turing-complete-bitcoin-contracts-1c6cb05edfca
3.Merkelized Abstract Syntax Trees
https://hashingit.com/elements/research-resources/2014-12-11-merkelized-abstract-syntax-trees.pdf
The author Wu Yue geek consults the promoter of the Chinese community, but unfortunately, most of the written materials about it can't explain the principle in a popular way at present. This paper is a simple summary after we read the white paper with only one page and consulted the materials related to trees. In order to facilitate readers to understand that some of the expressions are different from those described in the white paper, we assume that readers have some understanding and can understand the simple idea of fraud proof. First, summarize the ideas in a few words, and then release the unnecessary data under the chain. And when only the fraud proof that promises to challenge is stored in the storage chain, we only need to prove that the data needed to be uploaded is related to the existence of the chain, and then the main network will check whether these data are problematic or not, and whether the node where the data producer handles the transaction has evil behavior or not. All this follows the Occam razor principle, and the entity can be added as little as possible unless necessary. The so-called online fraud proof verification scheme based on popular summary. First of all, the computer processor is an input and output composed of a large number of logic gates. One of the core ideas of the system is to simulate the input and output effects of logic gates with bitcoin scripts. As long as the logic gates can be simulated, Turing machine can theoretically complete all the computable tasks, that is to say, as long as you have more people and more money, you can call a group of engineers to help you simulate logic gates with simple codes and then use a huge number of logic gates to realize or functions. This screenshot comes from a teaching game, Turing is complete, and the core content is to use logic gates. Especially the NAND gate to build a complete processor. Some people have compared the idea of making a processor with Redstone circuit in my world or equivalent to building blocks out of the Empire State Building in New York. It is said that it took someone a year to build a processor in my world. So why do you have to use analog or this is not very troublesome? This is because most bitcoins often choose to support or wait for high-level languages, but what can be run directly on the bitcoin chain at present is this simple one. A code example of a non-Turing complete programming language composed of special opcodes. If Bitcoin intends to verify fraud and inherit security to a great extent like waiting for Ethereum, it needs to directly verify a controversial transaction or a controversial opcode on the chain, so it is necessary to put the opcode corresponding to the adopted language on the bitcoin chain and run it again. The problem comes down to the effect of using this crude programming language of Bitcoin or other virtual machines. Therefore, from the perspective of compilation principle, To understand the scheme, it takes the opcode logic gate circuit translated from the opcode as an intermediate form between the opcode and the opcode. The white paper talks about the general idea of executing some controversial instructions on the bitcoin chain. The final simulated effect is to put the instructions that can only be processed on the bitcoin chain directly. Although this scheme is feasible, the difficulty lies in how to express all the opcodes with a large number of logic gates as an intermediate form and the combination of logic gates. Direct expression of some extremely complicated transaction processing flows may produce huge workload. Let's talk about another core mentioned in the white paper, that is, interactive fraud proof which is highly similar. Interactive fraud proof will involve a word called assertion. Generally speaking, the proposer is often acted as a sorter, who will post an assertion on the website to declare that some transaction data state conversion results are valid and correct. If someone thinks that the submitted assertion is wrong, the related data will be disputed at this time and. Exchange information in turn and search disputed data by dichotomy to quickly locate a very fine-grained operation instruction and its associated data fragments. The disputed operation instruction needs to be directly executed on the computer with its input parameters and the output results will be verified. Nodes will compare their calculated output results with the previously published output results. In this interactive fraud proof protocol called one-step fraud proof, the published data will be retrieved by dichotomy as soon as possible. Locate the controversial instruction and execution result, and finally send the one-step fraud proof to the interactive fraud proof flow chart on the component structure interpreted by the technical ambassador before the final verification reference. The idea of one-step fraud proof is relatively rough here, and the vast majority of trading instructions do not need to be re-verified in the chain, but one of the controversial data segment opcodes should be replayed when challenged. If the detection conclusion is that the previously released data has The problem is to drop the pledged assets. If there is a problem, the pledged assets can be dropped. If they do not respond to the challenge for a long time, the above effects can also be achieved through the contract on the Ethereum. After the interactive fraud proof and the one-step fraud proof are simply finished, we will talk about the tree and the huge amount of logic gates involved in a large number of transaction data processed under the chain, but we need some party directly. The formula proves that these data originally needed under the chain are not fabricated casually, which is a kind of data often mentioned in cryptography. First of all, let's say that the full name of the tree is to transform the tree involved in the compilation principle into the later form, so what is the tree? Its Chinese name is abstract syntax tree. Simply speaking, it is to subdivide a complex instruction into a bunch of basic operating units through lexical analysis and then organize it into a tree-like data structure. A simple case of a tree will make this simple operation. The calculation is subdivided into the underlying opcode data, and the tree is treed to support the tree. One advantage is that it can achieve efficient data compression. For example, if you want to publish a certain piece of data on the tree to the chain when necessary, but you have to convince the outside world that this piece of data really exists on the tree instead of being picked by you, what should you do? You just need to record the tree in advance on the chain and show it in the future to prove the relationship between a certain piece of data and the corresponding tree, so there is no need to store the complete tree on the chain. Just disclose it in advance as a data fragment to be presented when necessary, which can greatly reduce the amount of data and ensure that the data really exists in the tree, and only a small number of data fragments are disclosed on the chain instead of all data, which can play a good privacy protection effect. Refer to the example of the reason why data detention and fraud prove that smart contracts are not supported. The scheme of the tree tries to express all the logic gates with bitcoin scripts and then organize them into a huge tree. The bottom leaf diagram of this tree corresponds to the logic gates realized with bitcoin scripts, and every tree will be frequently published on the chain. 比特币今日价格行情网_okx交易所app_永续合约_比特币怎么买卖交易_虚拟币交易所平台
注册有任何问题请添加 微信:MVIP619 拉你进入群

打开微信扫一扫
添加客服
进入交流群
1.本站遵循行业规范,任何转载的稿件都会明确标注作者和来源;2.本站的原创文章,请转载时务必注明文章作者和来源,不尊重原创的行为我们将追究责任;3.作者投稿可能会经我们编辑修改或补充。














