
解析B^2新版技术路线图:比特币链下DA与验证层的必要性



作者:Faust;来源:极客web3
B^2 Hub:比特币链下的通用DA层与验证层
如今的比特币生态可谓是一片机会与骗局共存的蓝海,这个因铭文之夏而焕发生机的全新领域简直是一片肥沃的处女地,到处都弥漫着金钱的气息。随着今年1月比特币Layer2如雨后春笋般集体涌现,这片原本如荒芜原野的土地瞬间就成为了无数造梦者的摇篮。
但回归到最本质的问题:什么是Layer2,人们似乎始终没有达成共识。侧链是吗?索引器是吗?搭个桥的链就叫Layer2吗?一个依赖于比特币和以太坊的简易插件,可不可以当做一个Layer?这些问题就像一组难解的方程式,始终都没有一个确切的结局。
而按照以太坊和Celestia社区的思路,Layer2只是模块化区块链的特殊情况,在这种情况下,所谓的“二层”与“一层”之间会存在紧密的耦合关系,二层网络可以很大程度,或一定程度继承Layer1的安全性。至于安全性这个概念本身,可以拆解为细分的多个指标,包括:DA、状态验证、提款验证、抗审查性、抗重组等。
由于比特币网络本身存在诸多问题,其天生不利于支持较完备的Layer2网络。比如在DA上,比特币的数据吞吐量远低于以太坊,以其平均10min的出块时间来计算,比特币最大的数据吞吐量仅为6.8KB/s,差不多是以太坊的1/20,如此拥挤的区块空间自然而然造就了高昂的数据发布成本。
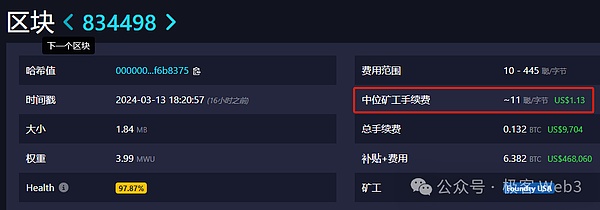
(比特币区块里的数据发布成本,甚至可以达到每KB 5美元)
如果Layer2直接把新增的交易数据发布到比特币区块里,既不能实现高吞吐量,也不能实现低手续费。所以要么就通过高度压缩,把数据尺寸压缩的尽可能小,再上传到比特币区块。目前Citrea采用了这种方案,它们声称,将把一段时间内的状态变化量(state diff),也就是多个账户上发生的状态变更结果,连同对应的ZK证明,一起上传到比特币链上。
这种情况下,任何人都可以从比特币主网下载state diff 和ZKP,验证其是否有效,但上链的数据尺寸却可以轻量化。
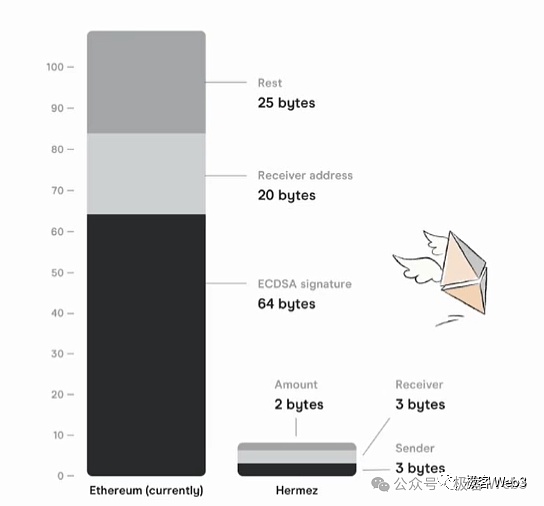
(前Polygon Hermez的白皮书中,说明了上述压缩方案的原理)
这种方案在极大程度压缩了数据尺寸的同时,最终还是容易遇到瓶颈。比如,假设在10分钟内发生了几万笔交易,使得上万个账户发生了状态变更,你最终还是要把这些账户的变化情况,汇总上传到比特币链上。虽然比起直接上传每笔交易数据,要轻量很多,但还是会产生很可观的数据发布成本。
所以很多比特币Layer2干脆就不把DA数据上传到比特币主网,直接采用Celestia等第三方DA层。而B^2采用了另一种方式,直接在链下搭建一个DA网络(数据分发网络),名为B^2 Hub。在B^2的协议设计中,交易数据或state diff等重要数据存放于链下,只向比特币主网上传这些数据的存储索引,以及数据hash(其实是merkle root,为了表述方便说成数据hash)。
这些数据hash和存储索引,以类似铭文的方式写入到比特币链上,只要你运行一个比特币节点,就可以把数据hash和存储索引下载到本地,根据索引值,能从B^2的链下DA层或存储层中,读取到原始数据。根据数据hash,你可以判断,自己从链下DA层获取的数据是否正确(能否和比特币链上的数据hash相对应)。通过这种简单的方式,Layer2可以避免在DA问题上过度依赖比特币主网,节约手续费成本并实现高吞吐量。

当然,有一点不可忽视,就是这种链下的第三方DA平台有可能搞数据扣留,拒绝让外界获取到新增的数据,这种场景有一个专用术语,叫“数据扣留攻击”,可以归纳为数据分发中的抗审查问题。不同的DA方案有不同的解决办法,但核心宗旨,都是要把数据尽可能快、尽可能广泛的传播出去,防止一小撮特权节点控制着数据获取权限不放。
按照B^2 Network官方新的路线图,其DA方案借鉴了Celestia。在后者的设计中,第三方的数据提供者会不断的向Celestia网络提供数据,Celestia出块者会把这些数据片段,组织为Merkle Tree的形态,塞到TIA区块里,广播给网络里的Validator/全节点。
由于这些数据比较多,区块比较大,大多数人运行不起全节点,只能运行轻节点。轻节点不同步完整区块,只同步一个区块头,写有Mekrle Tree的树根Root。
轻节点仅凭区块头,自然不知道Merkle Tree的全貌,不知道新增数据都有什么,无法验证数据是否有问题。但轻节点可以向全节点索要树上的某个叶子leaf。全节点会按照要求,把leaf和对应的Merkle Proof,一并提交给轻节点,让后者确信,这个leaf的确存在于Celestia区块里的Merkle Tree上,而不是被节点凭空杜撰出的虚假数据。
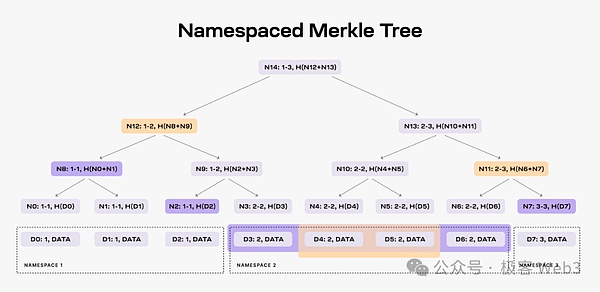
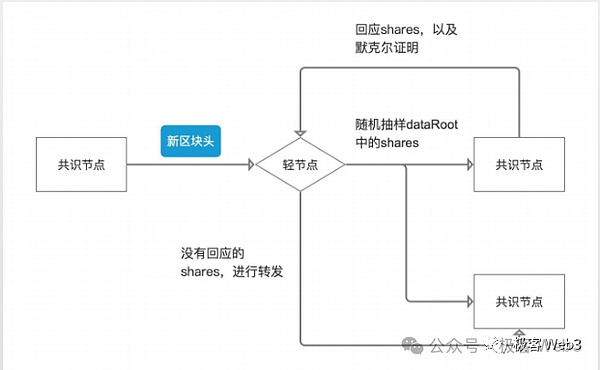
(图源:W3 Hitchhiker)
Celestia网络里存在大量的轻节点,这些轻节点可以向不同的全节点发起高频的数据采样,随机性的抽选Merkle Tree上的某几个数据片段。轻节点获取到了这些数据片段后,也可以传播给他能连接到的其他节点,这样就可以快速的把数据分发给尽可能多的人/设备,以此来实现高效的数据传播,只要足够多的节点都能快速获取最新的数据,人们就不用再信任一小撮数据提供者,这其实就是DA/数据分发的核心目的之一。
当然,仅凭上面描述的方案,还是存在攻击场景,因为它只能保证数据分发时,人们都能快速获取到数据,但无法保证数据的生产源头不作恶。比如,Celestia出块者可能在区块里掺杂一点垃圾数据,人们即便获取了区块中的全部数据片段,也无法还原出“本应包含”的完整数据集(注意:这里“本应”这个词很重要)。
进一步说,原始数据集中可能有100笔交易,其中某笔交易的数据没有被完整传播给外界。这时,只需要隐藏1%的数据片段,外界就无法解析出完整数据集。这正是最早的数据扣留攻击问题中,所探讨的场景。
其实,根据这里描述的场景来理解数据可用性,可用性这个词描述的是区块里的交易数据是否完整,是否可用,能否直接交由其他人去验证,而不是像很多人理解的那样,可用性代表区块链历史数据能否被外界读取到。所以,Celestia官方和L2BEAT创始人曾指出,数据可用性应该改名为数据发布,意指区块里是否发布了完整可用性的交易数据集。
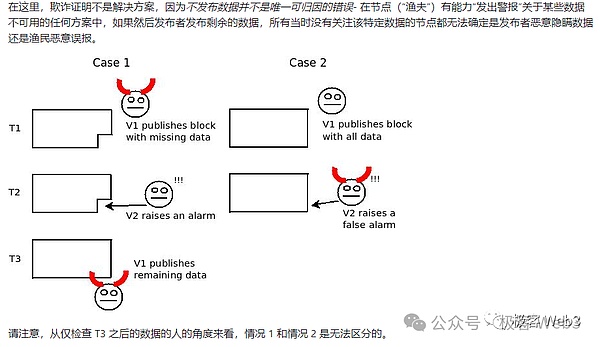
Celestia引入了二维纠删码,解决上面描述的数据扣留攻击。只要区块里包含的 1/4 的数据片段(纠删码)有效,人们就可以还原出对应的原始数据集。除非出块者在区块里掺杂 3/4 的垃圾数据片段,才能让外界无法还原出原始数据集,但这种情况下,区块里包含的垃圾数据太多了,很容易就会被轻节点们检测出来。所以对于区块生产者而言,还是不要作恶来的更好些,因为作恶几乎很快就被无数人察觉到。
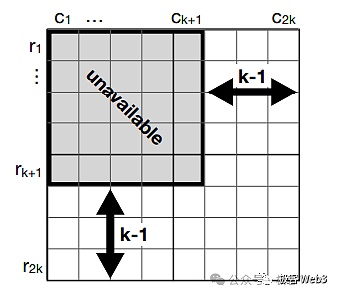
通过前面描述的方案,可以有效防止“数据分发平台”出现数据扣留,而B^2 Network未来会以Celestia的数据采样作为重要参考,可能结合KZG承诺等密码学技术,进一步降低轻节点执行数据采样和验证的成本。只要执行数据采样的节点足够多,就能让DA数据的分发变得有效且去信任。
当然,上述方案只解决了DA平台自身的数据扣留问题,但在Layer2的底层结构中,有能力发动数据扣留的不止DA平台,还有排序器(Sequencer)。在B^2 Network乃至大多数Layer2的工作流程中,新增数据是由排序器Sequencer产生的,它会把用户端发来的交易汇总处理,附带这些交易执行后的状态变更结果,打包成批次(batch),再发送给充当DA层的B^2 Hub节点们。
如果排序器一开始生成的batch就有问题,就还存在数据扣留的可能性,当然还包括其他形式的作恶场景。所以,B^2 的DA网络(B^2 Hub)收到排序器生成的Batch后,会先对验证Batch的内容,有问题就拒收。可以说,B^2 Hub 不但充当了类似于Celestia的DA层,也充当了链下的验证层,有点类似于CKB在RGB++协议中的角色。
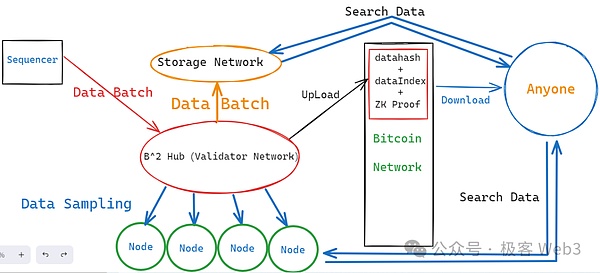
(不完整的B^2 Network底层结构图)
按照B^2 Network最新的技术路线图,B^2 Hub在收到并验证了Batch后,只保留一段时间,过了这个窗口期,Batch数据就会被过期淘汰,从B^2 Hub节点本地删除掉。为了解决类似于EIP-4844的数据淘汰及丢失问题,B^2 Network设置了一组存储节点,这些存储节点会负责永存Batch数据,这样一来,任何人在任何时候,都可以在存储网络中搜索到自己需要的历史数据。
不过,没有人会平白无故的运行B^2存储节点,如果想让更多人来运行存储节点,增强网络的去信任程度,就要提供激励机制;要提供激励机制,就要先想办法反作弊。比如,假如你提出了一套激励机制,任何人在自己的设备本地存储了数据,就可以获取奖励,可能有人在下载了数据后,又偷偷的把一部分数据删掉,却声称自己存储的数据是完整的,这就是最常见的作弊方法。
Filecoin通过名为PoRep和PoSt的证明协议,让存储节点向外界出示存储证明,证明自己在给定时间段内的确完整的保存了数据。但这种存储证明方案需要生成ZK证明,且计算复杂度很高,对存储节点的硬件设备会有较高要求,可能不是一个经济成本上可行的方法。
在B^2 Network的新版技术路线图中,存储节点会采用类似于Arweave的机制,需要争夺出块权来获取代币激励。如果存储节点私自删除了一些数据,则其成为下一个出块者的概率会降低,而保留数据最多的节点,越有可能成功出块,获取到更多的奖励。所以对于大多数存储节点而言,还是保留完整的历史数据集比较好。
当然,有激励的不只是存储节点,还包括前面提到的B^2 Hub节点,按照路线图,B^2 Hub会组建成一个Permissionless的POS网络,任何人只要质押了足够多的Token,就可以成为B^2 Hub或存储网络中的一员,通过这种方式,B^2 Network尝试在链下打造去中心化的DA平台及存储平台,并在未来集成B^2 以外的比特币Layer2,搭建通用的比特币链下DA层与数据存储层。
ZK与欺诈证明混用的状态验证方案
前面我们阐述了B^2 Network的DA解决方案,接下来我们将重点讲述其状态验证方案。所谓的状态验证方案,就是指Layer2如何保证自己的状态转换足够“去信任”。
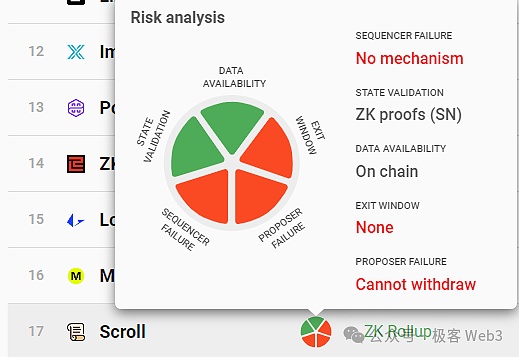
前面我们曾提到,在B^2 Network乃至大多数Layer2的工作流程中,新增数据是由排序器Sequencer产生的,它会把用户端发来的交易汇总处理,附带这些交易执行后的状态变更结果,打包成批次(batch),发送给Layer2网络中的其他节点,包括普通的Layer2全节点,以及B^2 Hub节点。
B^2 Hub节点在收到Batch数据后,会解析其内容并做出验证,这里就包含了前面提到的“状态验证”。其实状态验证,就是验证排序器生成的Batch中,记录的“交易执行后的状态变化”是否正确。如果B^2 Hub节点收到了包含错误状态的Batch,会将其拒收。
其实,B^2 Hub本质是一条POS公链,会有出块人和验证人、的分野。每隔一段时间,B^2 Hub的出块人会生成新的区块,并传播给其他节点(验证人),这些区块里包含了排序器提交的Batch数据。剩下的工作流程和前面提到的Celestia有些许类似,有很多外部的节点,频繁的向B^2 Hub节点索要数据片段,在这个过程中,Batch数据会被分发给很多节点设备,也包括前面提到的存储网络。
B^2 Hub中存在名为Committer(承诺人)的可轮换角色,它会把Batch的数据hash(其实是Merkle root),以及存储索引,以铭文的形式提交到比特币链上。只要你读取到这个数据hash和存储索引,就有办法在链下的DA层/存储层获取到完整的数据。假设链下有N个节点存放着Batch数据,只要其中1个节点愿意对外提供数据,就能让任何人获取到它需要的数据,这里的信任假设是1/N。
当然,我们不难发现,上述过程中,负责验证Layer2状态转换有效性的B^2 Hub,是独立于比特币主网的,只是一个链下的验证层,所以这个时候,Layer2的状态验证方案,在可靠性上无法等价于比特币主网。
一般而言,ZK Rollup可以完整的继承Layer1的安全性,但目前比特币链上只支持一些极为简单的计算,无法直接验证ZK证明,所以还没有哪个Lay\er2可以在安全模型上等价于以太坊的那种ZK Rollup,包括Citrea和BOB等。
目前看来,“比较可行”的思路是BitVM白皮书中所阐述的那样,复杂的计算过程挪到比特币链下,仅在必要时把某些简单的计算挪到链上进行。比如验证ZK证明时产生的计算痕迹,可以公开,交由外界去检查。如果人们发现其中某个比较细微的计算步骤有问题,就可以在比特币链上验证这道“有争议的计算”。这里面需要用比特币的脚本语言,模拟出EVM等特殊虚拟机的功能,消耗的工程量可能会非常巨大,但并不是不可行。
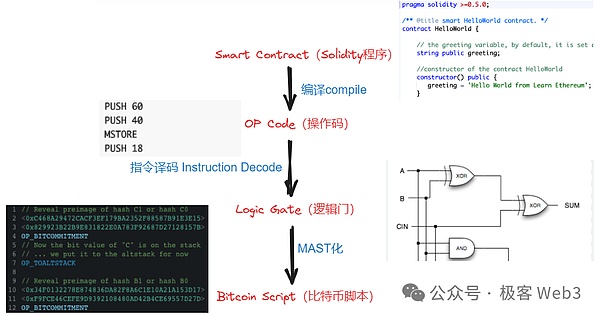
参考资料:《极简解读BitVM:如何在BTC链上验证欺诈证明(执行EVM或其他VM的操作码)》
在B^2 Network的技术方案中,排序器产生了新的Batch后,会转发给聚合器以及Prover,后者把Batch的数据验证过程ZK化,生成ZK证明,最终转发给B^2 Hub节点。B^Hub节点是EVM兼容的,通过Solidity合约来验证ZK Proof,这其中涉及的全部计算过程,会被拆分为非常底层的逻辑门电路形态,这些逻辑门电路又会以比特币脚本语言的形式表达出来,全部提交至吞吐量足够大的第三方DA平台中。
如果人们对这些披露出来的ZK验证痕迹存在疑问,觉得某个小步骤有错误,就可以在比特币链上进行“挑战”,要求比特币节点直接检查这个有问题的步骤,并适当做出惩罚。
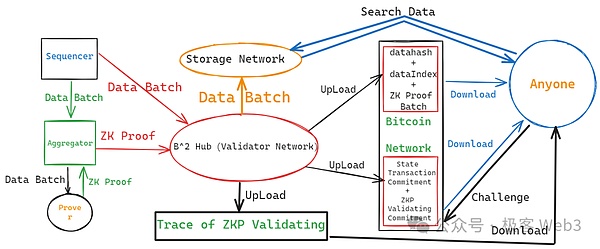
(B^2 Network的整体结构图,不包含数据采样节点)
那么是谁被惩罚呢?其实是Committer。在B^2 Network的设定中,Committer不但会把前面说的数据hash发布到比特币链上,还要把ZK证明的验证“承诺”发布到比特币主网。通过比特币Taproot的一些设定,你可以随时在比特币链上,对Committer发布的“ZK证明验证承诺”进行质疑和挑战。
这里解释下什么“承诺”(Commitment)。“承诺”的含义在于,某些人声称,某些链下数据是准确无误的,并在链上发布对应的声明,这个声明就是“承诺”,承诺值与特定的链下数据相绑定。在B^2的方案中,如果有人认为Committer发布的ZK验证承诺有问题,就可以进行挑战。
可能有人会问,前面不是提到B^2 Hub在收到Batch后,会直接验证其有效性吗,这里为何又要“多次一举”的验证ZK证明?为什么不直接把验证Batch的过程公开披露,让人们直接挑战,非要引入ZK证明干什么?这其实是为了把计算痕迹压缩的足够小,如果直接把验证Layer2交易、产生状态变更的计算流程,全部以逻辑门电路和比特币脚本的形式公开披露,将会产生极大的数据尺寸。而ZK化之后,可以把数据尺寸极大程度压缩后,再发布出去。
这里大致总结下B^2的工作流程:
B^2的排序器Sequencer负责产生新的Layer2区块,并将多个区块聚合为data batch(数据批次)。data batch会被送给聚合器Aggregator,以及B^Hub网络中的Validator节点。
The author comes from the common layer and verification layer under the geek bitcoin chain. Today's bitcoin ecology can be described as a blue ocean where opportunities and scams coexist. This new field, which is rejuvenated by the summer of inscriptions, is simply a fertile virgin land. The smell of money is everywhere. With the collective emergence of bitcoin this month, this land, which was originally deserted in Yuan Ye, has instantly become the cradle of countless dreamers, but it has returned to the most essential question. What is it that people never seem to reach a consensus? Is it a chain? Is it an indexer? Is it a bridge chain? Can a simple plug-in that relies on Bitcoin and Ethereum be regarded as one of these problems? Just like a group of difficult equations, there is always no exact ending. According to the idea of Ethereum and the community, it is only a special case of modular blockchain. In this case, there will be a close coupling relationship between the so-called second floor and the first floor. The second floor network can inherit the security to a great extent or to a certain extent. As for the concept of security itself, it can be. A number of indicators subdivided by disassembly include state verification, withdrawal verification, anti-censorship, anti-reorganization, etc. Because of many problems in the bitcoin network itself, it is inherently not conducive to supporting a relatively complete network. For example, the data throughput of Bitcoin in Shanghai is much lower than that of Ethereum, and the maximum data throughput of Bitcoin is only about the same as that of Ethereum. Such a crowded block space naturally creates high data publishing costs, and the data publishing costs in Bitcoin blocks can even be. In order to achieve the goal of each dollar, if the newly added transaction data is directly released to the bitcoin block, neither high throughput nor low handling fee can be achieved, so either the data size is compressed as small as possible through high compression and then uploaded to the bitcoin block. At present, this scheme is adopted, and they claim that the state change amount in a period of time, that is, the state change results in multiple accounts, will be uploaded to the bitcoin chain together with the corresponding certificates. In this case, anyone can download the data from the bitcoin chain. Download and verify whether it is effective, but the data size of the uplink can be lightweight. The principle of the above compression scheme is explained in the previous white paper. This scheme greatly compresses the data size, but it is still easy to encounter bottlenecks at the same time. For example, if tens of thousands of transactions occur in a minute, the status of tens of thousands of accounts will change. You will eventually summarize and upload the changes of these accounts to the bitcoin chain. Although it is much lighter than uploading each transaction data directly, it is still It will generate considerable data release cost, so many bitcoins simply don't upload data to the bitcoin main network and directly use the third-party layer, but adopt another way to directly build a network data distribution network under the chain. In the protocol design, transaction data or other important data are stored under the chain, and only the storage index and data of these data are uploaded to the bitcoin main network for convenience of expression. These data and storage index are written in a similar way to inscriptions. As long as you run a bitcoin node on the special currency chain, you can download the data and storage index to the local area. According to the index value, you can read the original data from the lower layer of the chain or the storage layer. According to the data, you can judge whether the data you obtained from the lower layer of the chain is correct or not, and whether it corresponds to the data on the bitcoin chain. This simple way can avoid over-reliance on the bitcoin main network, save the handling fee and achieve high throughput. Of course, one thing that cannot be ignored is the third in this chain. The platform may engage in data detention and refuse to let the outside world obtain the newly added data. There is a special term called data detention attack, which can be summarized as anti-censorship in data distribution. Different schemes have different solutions, but the core purpose is to spread the data as soon as possible and as widely as possible to prevent a small number of privileged nodes from controlling the access to data. According to the new official road map, the scheme draws lessons from the third-party data providers in the latter design. Those who provide data to the network will put these data fragments into blocks and broadcast them to all nodes in the network. Because these data are more and more blocks, most people can't afford to run the whole node. The light node can only run the light node. The light node is not synchronized with the complete block. Only the roots written in the block header are synchronized. The light node doesn't know what the new data is, and it is impossible to verify whether there is a problem with the new data. However, the light node can ask the whole node for a leaf on the tree. All nodes will submit the corresponding data to the light nodes as required, so that the latter can be sure that this data map does exist in the block, instead of being fabricated by the nodes out of thin air. There are a large number of light nodes in the source network. These light nodes can initiate high-frequency data sampling to different all nodes, and randomly select some data fragments on the light nodes. After obtaining these data fragments, the light nodes can also spread them to other nodes to which they can connect, so that the data can be distributed quickly. As long as enough nodes can get the latest data quickly, people don't have to trust a handful of data providers, which is actually one of the core purposes of data distribution. Of course, there are still attack scenarios only by the scheme described above, because it can only ensure that people can get the data quickly when distributing the data, but it can't guarantee that the production source of the data is not evil. For example, the blockers may mix a little junk data in the block, even if people get it. In addition, all the data fragments in the block can not restore the complete data set that should be included. Note that the word should be very important here. Furthermore, there may be a transaction in the original data set, and the data of a transaction has not been completely spread to the outside world. At this time, only the hidden data fragments are needed, and the outside world cannot analyze the complete data set. This is the scene discussed in the earliest data detention attack. In fact, according to the scene described here, the word data availability describes the block. Whether the transaction data in the block is complete and available can be directly verified by others, rather than whether the availability represents whether the historical data of the blockchain can be read by the outside world as many people understand. Therefore, the official and founder have pointed out that the data availability should be renamed as data release, which means whether the transaction data set with complete availability has been released in the block. Two-dimensional erasure codes has been introduced to solve the data detention attack described above. As long as the data fragments contained in the block are valid in erasure codes, people can restore the corresponding original data set, unless the junk data fragments doped by the blockers can make the outside world unable to restore the original data. 比特币今日价格行情网_okx交易所app_永续合约_比特币怎么买卖交易_虚拟币交易所平台
聚合器会将data Batch,发送给Prover节点,让后者生成对应的零知识证明。ZK证明随后会被发送给B^2的DA与验证者网络(B^2Hub)。
B^2Hub节点会验证聚合器发来的ZK Proof,能否和Sequencer发过来的Batch相对应。若两者可以对应,则通过验证。通过验证的Batch,其数据hash与存储索引,会被某个指定的B^Hub节点(称为Committer)发送至比特币链上。
B^Hub节点会将其验证ZK Proof的整个计算过程公开披露,将计算过程的Commitment发送到比特币链上,允许任何人对其进行挑战。如果挑战成功,则发布Commitment的B^Hub节点将受到经济惩罚(它在比特币链上的UTXO将被解锁并转移给挑战者)
B^2 Network的这种状态验证方案,一面引入了ZK,一面采用了欺诈证明,实际上属于混合型的状态验证方式。只要链下存在至少1个诚实的节点,在检测出错误后愿意发起挑战,就可以保证B^2 Network的状态转换是没有问题的。
按照西方比特币社区成员的看法,未来比特币主网可能会进行适当的分叉,以支持更多的计算功能,也许在未来,直接在比特币链上验证ZK证明会成为现实,届时将为整个比特币Layer2带来新的范式级变革。而B^2 Hub作为一个通用的DA层与验证层,不但可以作为B^2 Network的专用模块,还可以赋能其他比特币二层,在比特币Layer2的大争之世中,链下功能拓展层必将越来越重要,而B^Hub和BTCKB的涌现,或许才刚刚揭开这些功能拓展层的冰山一角。
注册有任何问题请添加 微信:MVIP619 拉你进入群

打开微信扫一扫
添加客服
进入交流群
1.本站遵循行业规范,任何转载的稿件都会明确标注作者和来源;2.本站的原创文章,请转载时务必注明文章作者和来源,不尊重原创的行为我们将追究责任;3.作者投稿可能会经我们编辑修改或补充。














