
区块链技术底层原理之Hash(散列),散列函数设计与开放寻址法



提到Hash(散列),相信大家都不陌生,作为最近很火的区块链技术最底层的原理之一,区块链的多个技术细节都用到了散列思想:区块链地址、交易散列、块散列、工作量证明、数据压缩、默克尔树等。同时哈希算法在信息加密,数据校验,负载均衡等领域也有着非常重要的应用。
Referring to Hash (the hash), it is believed that everyone is familiar, and that, as one of the lowest principles of the recently hot block chain technology, many of the technical details of the block chain have been applied to the hash idea: block chain addresses, trade hash, hash, workload certification, data compression, Merkel trees, etc. Also, Hashi algorithms have very important applications in such areas as information encryption, data validation, load balance, etc.
那么什么是散列,什么又是散列表呢?
So what's a hash and what's a ?
散列,是一种赖以高效组织数据并实现相关算法的重要思想。而散列表(Hash table,也叫哈希表),是根据键(Key)而直接访问在内存储存位置的数据结构。也就是说,它通过计算一个关于键值的函数,将所需查询的数据映射到表中一个位置来访问记录,这加快了查找速度。这个映射函数称做散列函数,存放记录的数组称做散列表。
The hash is an important idea based on the efficient organization of data and the achievement of related algorithms. The scattered list (Hash table, also called Hashi Table) directly accesss the data structure of storage locations in memory by key (Key). That is, it maps the required query data to one of the positions in the table by calculating a function of key values, which speeds up the search. This map function is called , the number of which is recorded as a scatter list.
首先,假设我们要设计一个系统来保存公司所有员工的信息,其中用员工的电话号码来作为保存信息的键值。同时我们还希望它能够有效地执行以下功能:
First, let's assume that we design a system for keeping information on all employees of the company, using the employee's phone number as the key to preserving the information. At the same time, we hope that it will be able to perform the following functions effectively:
1、可以插入员工的电话号码以及相应信息
1. The telephone number of the employee and the corresponding information can be inserted
2、可以搜索相关电话号码并获取其信息
2. Access to relevant telephone numbers and information
3、可以删除相关电话号码以及信息
3. The relevant telephone number and information can be deleted
我们很容易想到用数组来存储,以电话号码作为索引。于是我们可以制作如下的电话簿(为了方便我们假设电话号码由8位数字组成):
So we can make the following phone book (to allow us to assume that the number consists of eight digits):
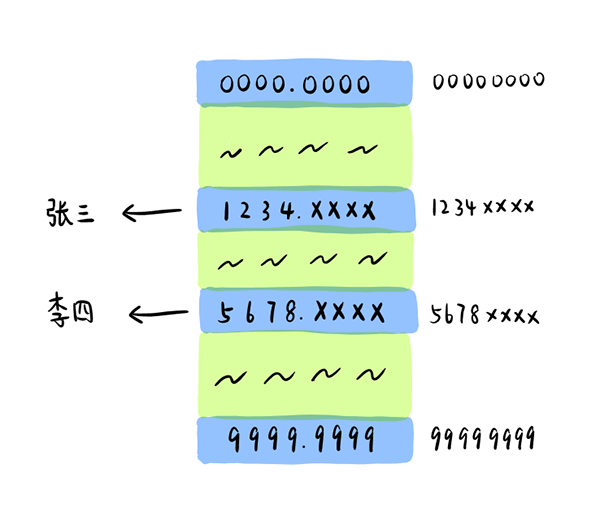
从上图可以看出,由于数组的索引值是连续的,所以为了存放所有可能的电话号码,我们需要申请的地址空间为[00000000]至[99999999],假如该公司有5w名员工,则会出现下面的情况:
As can be seen from the figure above, since the index values of the arrays are continuous, in order to store all possible telephone numbers, we need to apply for address space ranging from [10000000] to [99999999999], and if the company has 5w employees, the following situation will arise:
.可能的电话数 P=108P=108
. Potential telephone calls P=108P=108
.实际的电话数 N=54N=54
. Actual number of telephone calls N = 54N = 54
.空间利用率 R=N/P=0.05%R=N/P=0.05%
Space utilization rate R = N/P = 0.05% R = N/P = 0.05%
大家可以看到,使用数组虽然可以在常数时间找到我们想要的信息,但是空间的利用效率非常低。这是因为实际存储的关键字集合相对可能出现的关键字全域来说非常小,进而使得分配的大部分空间都将被浪费掉。
As you can see, while using arrays to find the information we want in constant hours, space is very inefficient. This is because the pool of actual stored keywords is very small compared to the possible keyword universe, which in turn allows most of the space allocated to be wasted.
那么我们如何在保证查找速度的同时,降低存储消耗呢?
So how do we reduce storage consumption while ensuring speed of search?
我们将直接通过数组索引查找元素的方式称为直接寻址,同时我们将其中每个存放元素的位置称为槽(slot).在直接寻址方式下,具有关键字k的元素被存放在槽k中。而在散列方式下,该元素存放在槽h(k)中,即利用散列函数h,由关键字k计算出槽的位置。
We call the direct location of the element by directly searching through the array of indexes, and we call the location of each element of the deposit the slot (slot). In the direct location mode, the element with key k is stored in slot k. In the hash mode, the element is stored in slot h (k), i.e., using the hash function h, the location of the slot is calculated by keyword k.
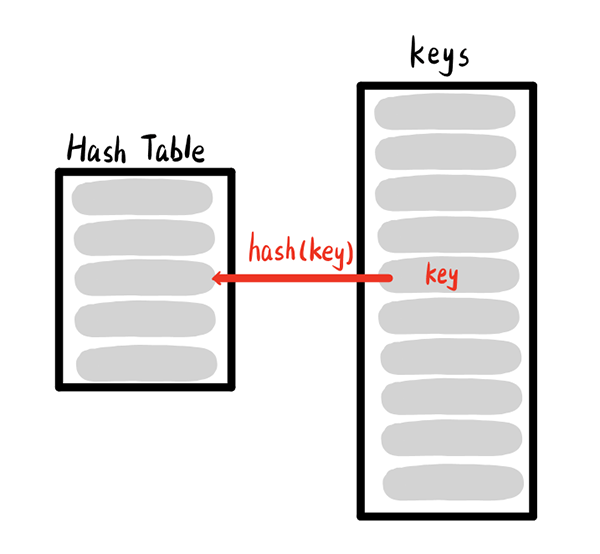

装载因子:给定一个能存放n个元素,具有m个槽位的散列表T,定义T的装载因子k=n/m
Load factor: Give a scattered list T with a m slot to store n elements and define T's loading factor k=n/m
那么装载因子应该如何选择呢?
So how should the loading factor be chosen?
.k越大,空间利用率越高,但是冲突发生的几率也越大。
The greater the.k, the higher the space utilization rate, the greater the likelihood of conflict.
.k越小,能够有效避免一定的冲突,但是空间利用率低。
The smaller the k, the more effective a conflict can be avoided, but space utilization is low.


为了实现散列表我们需要通过散列函数,那么我们应该如何设计一个散列函数呢?
How should we design a hash function if we need to pass a hash function in order to achieve the scattering list?
散列函数是一个映射的思想,为的是关键字空间的元素映射到散列表的地址空间。根据上面的例子可以看出,一般情况下关键字空间是大于散列表存储空间的。所以在大部分情况下,会出现多个关键字映射到同一个地址空间的情况,这就称之为冲突。
The hash function is a mapping idea to map the elements of the keyword space to the address space of the scattered list. As can be seen from the above examples, the keyword space is generally larger than the bulk list storage space. In most cases, therefore, multiple keyword mappings occur to the same address space, which is called conflict.
所以我们在设计散列函数时应该想办法尽可能降低冲突的概率,同时还需要制定相应的方法,以便冲突发生时给予解决。
So, in designing the hash function, we should find ways to minimize the probability of a conflict, and there is a need to develop a corresponding approach so that it can be resolved in the event of a conflict.
设计散列函数时应该注意下面几个方面:
When designing hash functions, the following should be noted:
确定性:关键字空间的任何一个关键字,都应该能够被唯一地映射到散列地址空间中的某一元素,这种映射关系应该是明确的。
快速性:对于求取上面的映射关系,我们希望能够在常数时间O(1)内完成。
Speed: for mapping above, we hope to be completed within constant time of O(1).
满射性:因为散列地址空间往往比关键字空间往往要小得多,所以我们希望通过散列函数的映射可以充分地覆盖整个散列空间。
Fullness: , since hash address space is often much smaller than keyword space, we hope that through the mapping of hash functions, the entire hash space will be adequately covered.
均匀性:为了充分利用散列地址空间和降低冲突概率。各关键字映射到散列表各位置的概率尽可能相等,即各关键字能够均匀地分布在散列空间中,进而避免很多元素在局部汇聚(clusting)现象。
homogeneity: is designed to make full use of hash address space and reduce the probability of conflict. The probability of the key words being mapd to the location of the dispersed list is as equal as possible, i.e., that the keywords are evenly distributed in hash space, thus avoiding the local convergence of many elements.
接下来,我们就按照这几条标准,介绍几种常用的散列函数
Next, we'll follow these criteria and introduce a few commonly used hash functions.
通过取k除以m的余数,将关键字k映射到m个槽中的某一个位置上,散列函数表示为:
By dividing k by the remaining number of m, the key k is mapd to a position in the m slot and the hash function is:
hash(key)=keyhash(key)=key
这里我们的m应该如何选择呢?
What should we do here?
经验证,当m取为素数时,数据对散列表的覆盖最充分,分布最均匀。
When m is taken as a prime number, it is verified that the data distribution list is the most well covered and evenly distributed.
但是除余法具有一定的局限性:
But the alternative has some limitations:
运用除余法会产生不动点,无论m的取值如何,总有hash(0)=0.因此,运用除余法,不同关键字映射到整个空间的概率也就不同了。
The use of the rest method produces no movement point, and regardless of the value of the m, there is always hash (0) = 0, so the probability of different key characters being mapd to the entire space is different with the application of the rest method.
在空间中相邻的关键码经过除余法映射到散列表中的地址也有很大概率相邻。而我们希望邻近的关键码,经过映射后散列地址应该分布应该更加随机,不再临近。
There is also a high probability that the key code adjacent to space will be extramurally mapd to the address in the scatter list. And we want the adjacent key code to be distributed more randomly and not closer.
该方法的散列函数如下:
The hash functions of this method are as follows:
hash(key)=((a?key)+b)hash(key)=((a?key)+b)
其中取m为素数,a>0,b>0,a%m!=0a>0,b>0,a%m!=0
= 0a> 0,b,gt; 0,a%m! = 0a,b,gt; 0,a%m! = 0
在上面的函数中,整数b为偏移量,因此消除了不动点。同时取整数a为间隔步长,进而使相邻点不再相邻。
In the function above, the integer b is an offset, so the no-move point is eliminated. At the same time, take the integer a as an interval step, so that the adjacent point is no longer adjacent.
直接选取关键字key中的某几位作为散列地址。
Select directly a few of the keywords that are used as hash addresses.


该方法先计算出关键字key的平方,然后选取中间的数位作为散列地址。
This method first calculates the square of the keyword key and then selects the intermediate number as the hash address.
为了使原关键字中的每一位对最终地址的选择具有更平均的影响力。由下图可以看出,对于一个关键字的平方运算,两侧的数位由更少的关键字数位决定,而中间的数位由更多的数位决定。所以选取中间的若干位作为散列地址,可以使得原关键字中的每一位对最终散列地址的决定具有均匀影响。
In order for each of the original keywords to have a more even impact on the selection of the final address, the figure below shows that, for the square operation of a key word, the number of the two sides is determined by a smaller number of key words, while the number of the middle is determined by a larger number. The selection of the intermediate number as a hash address allows each of the original keywords to have an even impact on the decision of the final hash address.
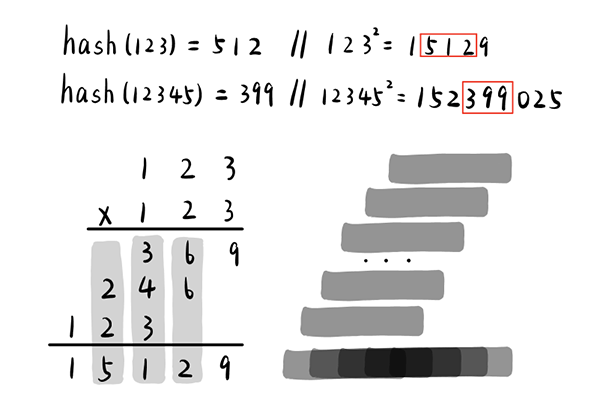
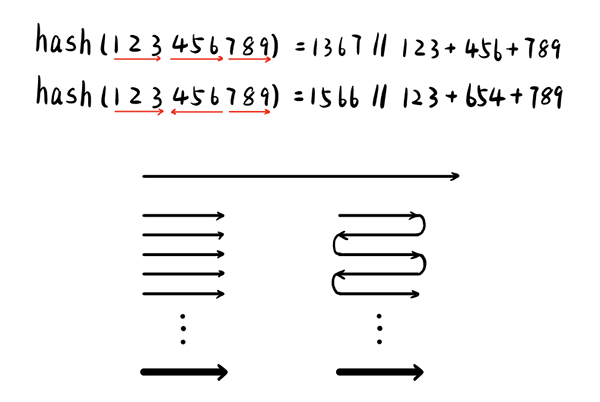
将原关键字中的数位分为若干组,然后将各组作为独立的整数,然后将它们的总和作为散列地址。或者也可以将关键字中分组的数位按照交替的方式作为整数取和。
Splits the digits in the original key word into several groups, then groups as separate integer numbers, and then the sum of them as hash addresses. Alternatively, the number of groups in the key word can be taken as integer numbers in alternating manner.

虽然上面介绍了许多优秀的散列函数,但是无论是采用哪种散列函数,都有可能发生冲突,因此我们必须对无法避免的冲突设计好解决方法。
While many excellent hash functions are described above, conflict is likely to occur regardless of which hash functions are used, so we must devise solutions to unavoidable conflicts.
前面我们讲过,对于数组,我们将其中每个位置称为槽(slot).所以为了防止冲突,我们可以再将每一个槽单元再分成多个槽位,存放该单元内冲突的关键字。
As we have already said, we call each of these slots a slot for arrays... So in order to prevent conflict, we can divide each cell into more than one slot and store the key words of the conflict in the cell.
每个单元中的槽位数目不多,依然可以保证O(1)的时间效率。但是事先准备多少个槽位,是无法预测的。预留过多,则会浪费大量的空间;预留过少,如果发生大规模冲突,则可能造成数据的丢失。
The small number of slots in each module still assures O(1) time efficiency. But it is impossible to predict how many slots are prepared in advance.


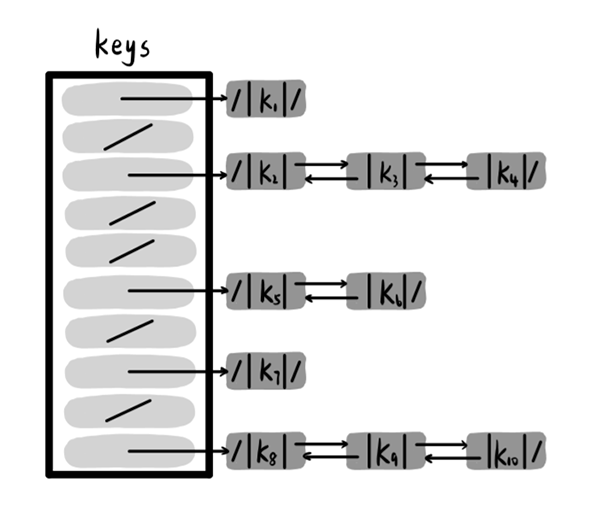
把散列到同一槽中的所有元素都放在一个链表中,每个槽位存放一个指针,指向该链表的表头。
All elements of the hash to the same slot are placed in a chain table, with each slot holding a pointer pointing to the top of the chain table.
运用链接法无需为每个槽单元预留多个槽位,同时链表的长度可以根据冲突情况自由伸缩,只要我们的内存足够,不论多少次冲突都可以解决。
There is no need to set aside multiple slots for each cell using the link method, while the length of the chain table can be freely scalded according to the circumstances of the conflict, as long as our memory is sufficient and no matter how many conflicts can be resolved.
由于我们需要事先存储指针,所以分配了额外的内存空间。同时在创建链表时,各节点是动态分配的,所以链表在空间中的分布也未必连续。
Because we need to pre-store the finger, we assign extra memory space. At the same time, nodes are dynamically distributed when creating the chain table, so the distribution of the chain table in space is not necessarily continuous.

在开放寻址法中,所有的元素都存放在散列表里,只要有必要,任何的槽位都可以存放任何关键字。因此,表的大小在任何时候都必须大于或等于键的总数。也就是说,开放寻址中的装载因子总是小于等于1的。
In the Open Address Method, all elements are stored in the Dispersal List, and any slot can store any keyword if necessary. Therefore, the size of the table must be greater than or equal to the number of keys at any given time. That is, the load factor in the Open Search is always less than equal to 1.
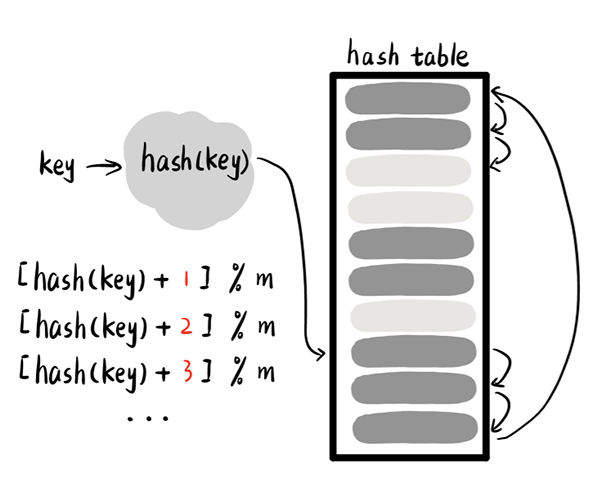
1.线性试探(linear probing)
一旦发生冲突,就尝试后一邻接槽单元,直到到达一个空槽,即成功。该方法仅在散列表内部解决冲突,无需申请额外的内存空间。只要在散列表中存在空槽,插入元素总能存入。
In the event of a conflict, the next adjacent slot unit is tried until it reaches an empty slot, which is successful. This method resolves the conflict only within the discrete list and does not require additional memory space. As long as there are empty slots in the dispersed list, the inserted element can always be deposited.
但是由于冲突元素的插入,虽然避免了当前冲突,但是可能会导致其他冲突,形成连锁反应。且有很大可能出现数据聚集堆积的情况。解决办法是我们可以通过控制装载因子的值来避免冲突和堆积等现象的出现。
But because the elements of the conflict are inserted, while avoiding the current conflict, they may lead to other conflicts, creating a chain reaction. There is a high probability that there will be a build-up of data. The solution is that we can avoid conflict and accumulation by controlling the value of the loading factor.
在线性试探中,如果需要删除某个元素。我们需要在删除元素后,做上标记。在之后进行查找的过程中,如果遇到已标记删除的槽,应该越过继续查找,直到找到关键字所在槽或者遇到空桶就停下,表示该元素并不在散列表中。
On-line search, if you want to delete an element. We need to mark the element after it has been removed. During the subsequent search, if you encounter a marked deleted slot, you should continue to search beyond the slot until you find it or stop with an empty bucket, indicating that the element is not in the scattered list.

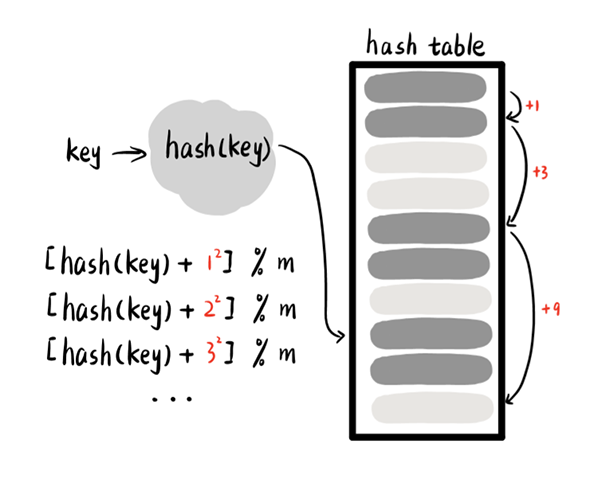
2.平方试探(quadratic probing)
和线性试探不同,平方试探是以平方数为间距,确定下一桶单元位置。这样的话,一旦发生冲突,就可以快速找到空桶并插入,这一方法有效地缓解了数据聚集现象的发生。但是如果采用平方试探,并没有对每个槽进行试探,因此有的空槽不一定会被找到。所以为了尽量使所有槽都能被找到,应该要求装载因子应该足够小。
Unlike linear tests, the square search is a distance between squares and determines the location of the next drum. In this case, when there is a conflict, an empty barrel can be quickly found and inserted, a method that effectively mitigates the accumulation of data. But if a square test is used, no pits are tested, so some empty slots may not be found. So, in order to try to locate all tanks, the loading factor should be small enough.
双重散列是用于开放寻址法的最好方法之一,所谓双重散列,意思就是不仅要使用一个散列函数。我们需要使用两个散列函数 hash1(key)hash1(key),hash2(key)hash2(key).我们先用第一个散列函数,如果发生冲突,则再利用第二个散列函数。
Double hash is one of the best ways to open the location method, which means not just one hash function. We need to use two hash1 (key) hash1 (key), hash2 (key) hash2(key). We use the first hash function first and, in case of conflict, the second hash function.


注册有任何问题请添加 微信:MVIP619 拉你进入群

打开微信扫一扫
添加客服
进入交流群
1.本站遵循行业规范,任何转载的稿件都会明确标注作者和来源;2.本站的原创文章,请转载时务必注明文章作者和来源,不尊重原创的行为我们将追究责任;3.作者投稿可能会经我们编辑修改或补充。








